2.11. Linear algebra games including SVD for PCA¶
Some parts adapted from Computational-statistics-with-Python.ipynb, which is itself from a course taught at Duke University; other parts from Peter Mills’ blog.
The goal here is to practice some linear algebra manipulations by hand and with Python, and to gain some experience and intuition with the Singular Value Decomposition (SVD). \(\newcommand{\Amat}{\mathbf{A}} \newcommand{\AmatT}{\mathbf{A^\top}} \newcommand{\thetavec}{\boldsymbol{\theta}} \newcommand{\Sigmamat}{\mathbf{\Sigma}} \newcommand{\Yvec}{\mathbf{Y}} \)
Preliminary exercise: manipulations using the index form of matrices¶
If you haven’t already done this earlier, prove that the Maximum Likelihood Estimate (MLE) for \(\chi^2\) given by
is
Here \(\thetavec\) is a \(m\times 1\) matrix of parameters (i.e., there are \(m\) parameters), \(\Sigmamat\) is the \(m\times m\) covariance matrix, \(\Yvec\) is a \(N\times 1\) matrix of observations (data), and \(\Amat\) is an \(N\times m\) matrix
where \(N\) is the number of observations. The idea is to do this with explicit indices for vectors and matrices, using the Einstein summation convention.
A suggested approach:
Write \(\chi^2\) in indices: \(\chi^2 = (Y_i - A_{ij}\theta_j)\Sigma^{-1}_{ii'}(Y_{i'}- A_{i'j'}\theta_{j'})\), where summations over repeated indices are implied (be careful of transposes). How do we see that \(\chi^2\) is a scalar?
Find \(\partial\chi^2/\partial \theta_k = 0\) for all \(k\), using \(\partial\theta_j/\partial\theta_k = 0\). Isolate the terms with one component of \(\thetavec\) from those with none.
You should get the matrix equation \( (\AmatT \Sigmamat^{-1} \Yvec) = (\AmatT \Sigmamat^{-1} \Amat)\thetavec\). At this point you can directly solve for \(\thetavec\). Why can you do this now?
If you get stuck, see Dick’s notes from the Parameter Estimation III lecture.
SVD basics¶
A singular value decomposition (SVD) decomposes a matrix \(A\) into three other matrices (we’ll skip the boldface font here):
where (take \(m > n\) for now)
\(A\) is an \(m\times n\) matrix;
\(U\) is an \(m\times n\) (semi)orthogonal matrix;
\(S\) is an \(n\times n\) diagonal matrix;
\(V\) is an \(n\times n\) orthogonal matrix.
Comments and tasks:
Verify that these dimensions are compatible with the decomposition of \(A\).
The
scipy.linalgfunctionsvdhas a Boolean argumentfull_matrices. IfFalse, it returns the decomposition above with matrix dimensions as stated. IfTrue, then \(U\) is \(m\times m\), \(S\) is \(m \times n\), and \(V\) is \(n\times n\). We will use thefull_matrices = Falseform here. Can you see why this is ok?Recall that orthogonal means that \(U^\top U = I_{n\times n}\) and \(V V^\top = I_{n\times n}\). Are \(U U^\top\) and \(V^\top V\) equal to identity matrices?
In index form, the decomposition of \(A\) is \(A_{ij} = U_{ik} S_k V_{jk}\), where the diagonal matrix elements of \(S\) are \(S_k\) (make sure you agree).
These diagonal elements of \(S\), namely the \(S_k\), are known as singular values. They are ordinarily arranged from largest to smallest.
\(A A^\top = U S^2 U^\top\), which implies (a) \(A A^\top U = U S^2\).
\(A^\top A = V S^2 V^\top\), which implies (b) \(A^\top A V = V S^2\).
If \(m > n\), we can diagonalize \(A^\top A\) to find \(S^2\) and \(V\) and then find \(U = A V S^{-1}\). If \(m < n\) we switch the roles of \(U\) and \(V\).
Quick demonstations for you to do or questions to answer:
Show from equations (a) and (b) that both \(U\) and \(V\) are orthogonal and that the eigenvalues, \(\{S_i^2\}\), are all positive.
Show that if \(m < n\) there will be at most \(m\) non-zero singular values.
Show that the eigenvalues from equations (a) and (b) must be the same.
A key feature of the SVD for us here is that the sum of the squares of the singular values equals the total variance in \(A\), i.e., the sum of squares of all matrix elements (squared Frobenius norm). Thus the size of each says how much of the total variance is accounted for by each singular vector. We can create a truncated SVD containing a percentage (e.g., 99%) of the variance:
where \(p < n\) is the number of singular values included. Typically this is not a large number.
Geometric interpretation of SVD¶
Geometric interpretation of SVD
rotate orthogonal frame \(V\) onto standard frame
scale by \(S\)
rotate standard frame into orthogonal frame \(U\)
Consider the two-dimensional case: \(\mathbf{x_1} = (x_1, y_1)\), \(\mathbf{x_2} = (x_2, y_2)\). We can fit these to an ellipse with major axis \(a\) and minor axis \(b\), made by stretching and rotating a unit circle. Let \(\mathbf{x'} = (x', y')\) be the transformed coordinates:
In index form this is \(x'_j = \frac{1}{m_j} x_i R_{ij}\) or (clockwise rotation):
The equation for a unit circle \(\mathbf{x' \cdot x'} = 1\) becomes
With \(X = \left(\begin{array}{cc} x_1 & y_1 \\ x_2 & y_2 \end{array} \right)\) we find the matrix equation:
which is just a rearrangement of the equation from above, \(A^\top A V = V S^2\).
Interpretation: If \(A\) is considered to be a collection of points, then the singular values are the axes of a least-squares fitted ellipsoid while \(V\) is its orientation. The matrix \(U\) is the projection of each of the points in \(A\) onto the axes.
Solving matrix equations with SVD¶
We can solve for \(\mathbf{x}\):
or \(x_i = \sum_j \frac{V_{ij}}{S_j} \sum_k U_{kj} b_k\). The value of this solution method is when we have an ill-conditioned matrix, meaning that the smallest eigenvalues are zero or close to zero. We can throw away the corresponding components and all is well! See also.
Comments:
If we have a non-square matrix, it still works. If \(m\times n\) with \(m > n\), then only \(n\) singular values.
If \(m < n\), then only \(n\) singular values.
This is like solving
which is called the normal equation. It produces the solution to \(\mathbf{x}\) that is closest to the origin, or
Task: prove these results (work backwards from the last equation as a least-squares minimization).
Data reduction¶
For machine learning (ML), there might be several hundred variables but the algorithms are made for a few dozen. We can use SVD in ML for variable reduction. This is also the connection to sloppy physics models. In general, our matrix \(A\) can be closely approximated by only keeping the largest of the singular values. We’ll see that visually below using images.
Python imports¶
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import scipy.linalg as la
from sklearn.decomposition import PCA
Generate random matrices and verify the properties for SVD given above. Check what happens when \(m > n\).
A = np.random.rand(9, 4)
print('A = ', A)
Ap = np.random.randn(5, 3)
print('Ap = ', Ap)
A = [[0.95218157 0.58728431 0.04006694 0.48436912]
[0.85994846 0.11070015 0.15762213 0.0474621 ]
[0.67903393 0.13127929 0.42194086 0.18993066]
[0.56657883 0.57242943 0.41189057 0.03014707]
[0.02704504 0.82790384 0.92956035 0.38784498]
[0.78650741 0.1041311 0.91697793 0.12746612]
[0.94289258 0.06594576 0.69817497 0.6211515 ]
[0.37499935 0.0081692 0.43109713 0.72768901]
[0.00374962 0.05287512 0.53760618 0.95302442]]
Ap = [[ 8.15988596e-01 -5.38974619e-01 1.13170353e+00]
[-1.47605096e+00 -1.25647001e+00 -4.41326938e-01]
[ 1.11134677e-03 9.34373245e-01 3.31458562e-02]
[ 6.24226168e-01 -2.51860257e-02 1.19979922e+00]
[-5.67028837e-01 -7.96975541e-01 2.43410917e-01]]
Check the definition of scipy.linalg.svd with shift-tab-tab.
# SVD from scipy.linalg
U, S, V_trans = la.svd(A, full_matrices=False)
Up, Sp, Vp_trans = la.svd(Ap, full_matrices=False)
print(U.shape, S.shape, V_trans.shape)
(9, 4) (4,) (4, 4)
# Transpose with T, matrix multiplication with @
print(U.T @ U)
[[ 1.00000000e+00 -4.95626453e-17 -2.61077940e-17 -2.23048948e-17]
[-4.95626453e-17 1.00000000e+00 -8.01249597e-17 1.12569317e-16]
[-2.61077940e-17 -8.01249597e-17 1.00000000e+00 -1.49966281e-16]
[-2.23048948e-17 1.12569317e-16 -1.49966281e-16 1.00000000e+00]]
# Here's one way to suppress small numbers from round-off error
np.around(U.T @ U, decimals=15)
array([[ 1., -0., -0., -0.],
[-0., 1., -0., 0.],
[-0., -0., 1., -0.],
[-0., 0., -0., 1.]])
# Predict this one before evaluating!
print(U @ U.T)
[[ 0.74667979 0.21883191 0.05830129 0.22708317 0.01070121 -0.27096879
0.06858303 0.08763823 0.01931773]
[ 0.21883191 0.25520749 0.1523606 0.10813043 -0.17601662 0.14784511
0.16686567 -0.00227415 -0.16307645]
[ 0.05830129 0.1523606 0.13461893 0.07979593 -0.01951947 0.21981423
0.1776961 0.0429624 -0.03735657]
[ 0.22708317 0.10813043 0.07979593 0.2934234 0.29980341 0.10107509
-0.01034437 -0.1074956 -0.16105649]
[ 0.01070121 -0.17601662 -0.01951947 0.29980341 0.79644628 0.10518275
-0.08717585 -0.02934142 0.1457264 ]
[-0.27096879 0.14784511 0.21981423 0.10107509 0.10518275 0.57376648
0.26920239 0.00859447 -0.08446639]
[ 0.06858303 0.16686567 0.1776961 -0.01034437 -0.08717585 0.26920239
0.34484081 0.22429107 0.17697145]
[ 0.08763823 -0.00227415 0.0429624 -0.1074956 -0.02934142 0.00859447
0.22429107 0.28382454 0.3618566 ]
[ 0.01931773 -0.16307645 -0.03735657 -0.16105649 0.1457264 -0.08446639
0.17697145 0.3618566 0.57119228]]
Go on and check the other claimed properties.
For example, is \(A = U S V^\top\)? (Note: you’ll need to make \(S\) a matrix with np.diag(S).)
# Check the other properties, changing the matrix size and shapes.
For a square matrix, compare the singular values in \(S\) to the eigenvalues from la.eig. What do you conclude? Now try this for a symmetric matrix (note that a matrix plus its transpose is symmetric).
SVD applied to images for compression¶
Read in ../../_images/elephant.jpg as a gray-scale image. The image has \(1066 \times 1600\) values. Using SVD, recreate the image with a relative error of less than 0.5%. What is the relative size of the compressed image as a percentage?
from skimage import io
img = io.imread('../../_images/elephant.jpg', as_gray=True)
plt.imshow(img, cmap='gray');
print('shape of img: ', img.shape)
shape of img: (1066, 1600)

# turn off axis
plt.imshow(img, cmap='gray')
plt.gca().set_axis_off()

# Do the svg
U, S, Vt = la.svd(img, full_matrices=False)
# Check the shapes
U.shape, S.shape, Vt.shape
((1066, 1066), (1066,), (1066, 1600))
# Check that we can recreate the image
img_orig = U @ np.diag(S) @ Vt
print(img_orig.shape)
plt.imshow(img_orig, cmap='gray')
plt.gca().set_axis_off()
(1066, 1600)

Here’s how we can efficiently reduce the size of the matrices. Our SVD should be sorted, so we are keeping only the largest singular values up to a point.
# Pythonic way to figure out when we've accumulated 99.5% of the result
k = np.sum(np.cumsum((S**2)/(S**2).sum()) <= 0.995)
Aside: dissection of the Python statement to find the index for accumulation¶
test = np.array([5, 4, 3, 2, 1])
threshold = 0.995
print('initial matrix, in descending magnitude: ', test)
print( 'fraction of total sum of squares: ', (test**2) / (test**2).sum() )
print( 'cumulative fraction: ', np.cumsum((test**2) / (test**2).sum()) )
print( 'mark entries as true if less than or equal to threshold: ',
(np.cumsum((test**2) / (test**2).sum()) <= threshold) )
print( 'sum up the Trues: ',
np.sum(np.cumsum((test**2) / (test**2).sum()) <= threshold) )
print( 'The last result is the index we are looking for.')
initial matrix, in descending magnitude: [5 4 3 2 1]
fraction of total sum of squares: [0.45454545 0.29090909 0.16363636 0.07272727 0.01818182]
cumulative fraction: [0.45454545 0.74545455 0.90909091 0.98181818 1. ]
mark entries as true if less than or equal to threshold: [ True True True True False]
sum up the Trues: 4
The last result is the index we are looking for.
# Let's plot the eigenvalues and mark where k is
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(1,1,1)
ax.semilogy(S, color='blue', label='eigenvalues')
ax.axvline(k, color='red', label='99.5% of the variance');
ax.set_xlabel('eigenvalue number')
ax.legend()
fig.tight_layout()
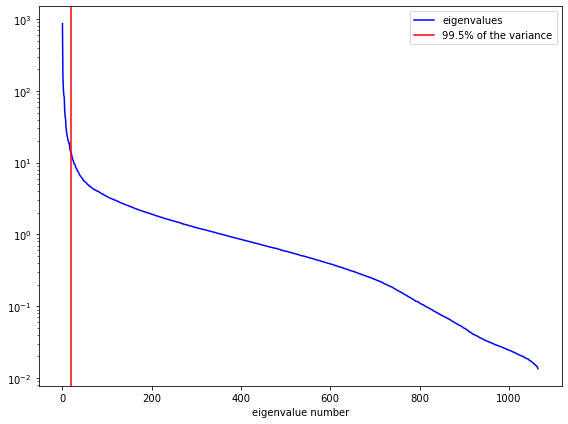
Now keep only the most significant eigenvalues (those up to k).
img2 = U[:,:k] @ np.diag(S[:k])@ Vt[:k, :]
img2.shape
(1066, 1600)
plt.imshow(img2, cmap='gray')
plt.gca().set_axis_off();

k99 = np.sum(np.cumsum((S**2)/(S**2).sum()) <= 0.99)
img99 = U[:,:k99] @ np.diag(S[:k99])@ Vt[:k99, :]
plt.imshow(img99, cmap='gray')
plt.gca().set_axis_off();

Let’s try another interesting picture …
fraction_kept = 0.995
def svd_shapes(U, S, V, k=None):
if k is None:
k = len(S)
U_shape = U[:,:k].shape
S_shape = S[:k].shape
V_shape = V[:,:k].shape
print(f'U shape: {U_shape}, S shape: {S_shape}, V shape: {V_shape}')
img_orig = io.imread('../../_images/Dick_in_tailcoat.jpg')
img = io.imread('../../_images/Dick_in_tailcoat.jpg', as_gray=True)
U, S, V = la.svd(img)
svd_shapes(U, S, V)
k995 = np.sum(np.cumsum((S**2)/(S**2).sum()) <= fraction_kept)
print(f'k995 = {k995}')
img995 = U[:,:k995] @ np.diag(S[:k995])@ V[:k995, :]
print(f'img995 shape = {img995.shape}')
svd_shapes(U, S, V, k995)
fig = plt.figure(figsize=(12,6))
ax1 = fig.add_subplot(1,3,1)
ax1.imshow(img_orig)
ax1.set_axis_off()
ax2 = fig.add_subplot(1,3,2)
ax2.imshow(img, cmap='gray')
ax2.set_axis_off()
ax3 = fig.add_subplot(1,3,3)
ax3.imshow(img995, cmap='gray')
ax3.set_axis_off()
fig.tight_layout()
U shape: (3088, 2320), S shape: (2320,), V shape: (2320, 2320)
k995 = 24
img995 shape = (3088, 2320)
U shape: (3088, 24), S shape: (24,), V shape: (2320, 24)

# Let's plot the eigenvalues and mark where k is
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(1,1,1)
ax.semilogy(S, color='blue', label='eigenvalues')
ax.axvline(k995, color='red', label='99.5% of the variance');
ax.set_xlabel('eigenvalue number')
ax.legend()
fig.tight_layout()
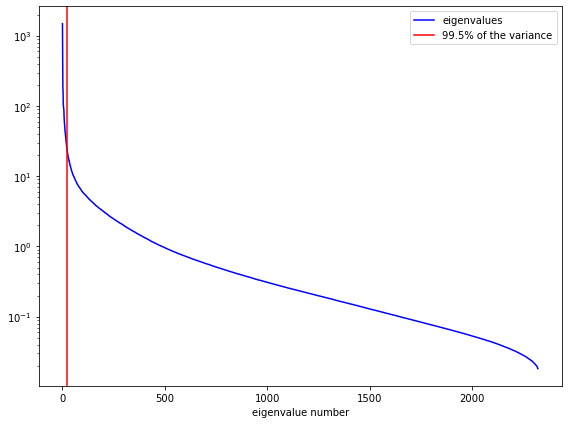
Things to do:¶
Get your own figure and duplicate these results. Then play!
As you reduce the percentage of the variance kept, what features of the image are retained and what are lost?
See how small you can make the percentage and still recognize the picture.
How is this related to doing a spatial Fourier transform, applying a low-pass filter, and transforming back. (Experts: try this!)
Covariance, PCA and SVD¶
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import scipy.linalg as la
np.set_printoptions(precision=3)
Recall the formula for covariance
where \(\text{Cov}(X, X)\) is the sample variance of \(X\).
def cov(x, y):
"""Returns covariance of vectors x and y)."""
xbar = x.mean()
ybar = y.mean()
return np.sum((x - xbar)*(y - ybar))/(len(x) - 1)
X = np.random.random(10)
Y = np.random.random(10)
np.array([[cov(X, X), cov(X, Y)], [cov(Y, X), cov(Y,Y)]])
array([[0.082, 0.033],
[0.033, 0.104]])
np.cov(X, Y) # check against numpy
array([[0.082, 0.033],
[0.033, 0.104]])
# Extension to more variables is done in a pair-wise way
Z = np.random.random(10)
np.cov([X, Y, Z])
array([[ 0.082, 0.033, -0.041],
[ 0.033, 0.104, 0.004],
[-0.041, 0.004, 0.089]])
Eigendecomposition of the covariance matrix¶
# Zero mean but off-diagonal correlation matrix
mu = [0,0]
sigma = [[0.6,0.2],[0.2,0.2]]
n = 1000
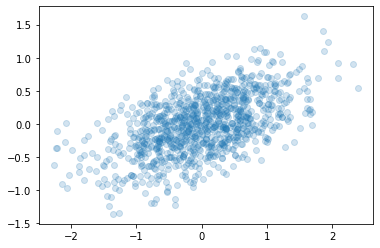
x = np.random.multivariate_normal(mu, sigma, n).T
plt.scatter(x[0,:], x[1,:], alpha=0.2);
# Find the covariance matrix of the matrix of points x
A = np.cov(x)
# m = np.array([[1,2,3],[6,5,4]])
# ms = m - m.mean(1).reshape(2,1)
# np.dot(ms, ms.T)/2
# Find the eigenvalues and eigenvectors
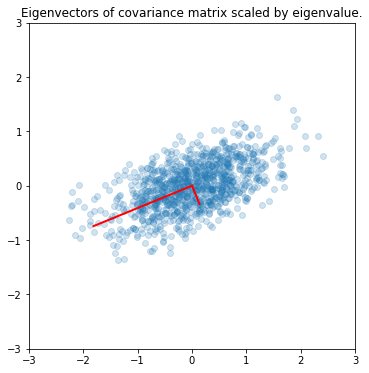
e, v = la.eigh(A)
fig = plt.figure(figsize=(6,6))
ax = fig.add_subplot(1,1,1)
ax.scatter(x[0,:], x[1,:], alpha=0.2)
for e_, v_ in zip(e, v.T):
ax.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
ax.axis([-3,3,-3,3])
ax.set_aspect(1)
ax.set_title('Eigenvectors of covariance matrix scaled by eigenvalue.');
PCA (from Duke course)¶
“Principal Components Analysis” (PCA) basically means to find and rank all the eigenvalues and eigenvectors of a covariance matrix. This is useful because high-dimensional data (with \(p\) features) may have nearly all their variation in a small number of dimensions \(k<p\), i.e. in the subspace spanned by the eigenvectors of the covariance matrix that have the \(k\) largest eigenvalues. If we project the original data into this subspace, we can have a dimension reduction (from \(p\) to \(k\)) with hopefully little loss of information.
Numerically, PCA is typically done using SVD on the data matrix rather than eigendecomposition on the covariance matrix. Numerically, the condition number for working with the covariance matrix directly is the square of the condition number using SVD, so SVD minimizes errors.”
For zero-centered vectors,
and so the covariance matrix for a data set \(X\) that has zero mean in each feature vector is just \(XX^T/(n-1)\).
In other words, we can also get the eigendecomposition of the covariance matrix from the positive semi-definite matrix \(XX^T\).
Note: Here \(x\) is a matrix of row vectors.
X = np.random.random((5,4))
X
array([[0.122, 0.071, 0.413, 0.139],
[0.583, 0.136, 0.76 , 0.709],
[0.445, 0.743, 0.198, 0.898],
[0.164, 0.681, 0.378, 0.407],
[0.766, 0.978, 0.232, 0.057]])
Y = X - X.mean(axis=1)[:, None] # eliminate the mean
print(Y.mean(axis=1))
[ 0.000e+00 -5.551e-17 5.551e-17 -5.551e-17 8.327e-17]
np.around(Y.mean(1), 5)
array([ 0., -0., 0., -0., 0.])
Y
array([[-0.065, -0.115, 0.226, -0.047],
[ 0.036, -0.411, 0.213, 0.162],
[-0.126, 0.172, -0.373, 0.327],
[-0.244, 0.274, -0.029, -0.001],
[ 0.258, 0.47 , -0.276, -0.451]])
Check that the covariance matrix is unaffected by removing the mean:
np.cov(X)
array([[ 0.024, 0.028, -0.037, -0.007, -0.037],
[ 0.028, 0.081, -0.034, -0.043, -0.105],
[-0.037, -0.034, 0.097, 0.03 , 0.001],
[-0.007, -0.043, 0.03 , 0.045, 0.025],
[-0.037, -0.105, 0.001, 0.025, 0.189]])
np.cov(Y)
array([[ 0.024, 0.028, -0.037, -0.007, -0.037],
[ 0.028, 0.081, -0.034, -0.043, -0.105],
[-0.037, -0.034, 0.097, 0.03 , 0.001],
[-0.007, -0.043, 0.03 , 0.045, 0.025],
[-0.037, -0.105, 0.001, 0.025, 0.189]])
# Find the eigenvalue and eigenvectors
e1, v1 = np.linalg.eig(np.dot(x, x.T)/(n-1))
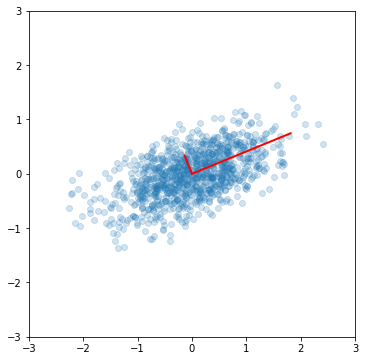
Principal components¶
Principal components are simply the eigenvectors of the covariance matrix used as basis vectors. Each of the original data points is expressed as a linear combination of the principal components, giving rise to a new set of coordinates.
# Check that we reproduce the previous result
fig = plt.figure(figsize=(6,6))
ax = fig.add_subplot(1,1,1)
ax.scatter(x[0,:], x[1,:], alpha=0.2)
for e_, v_ in zip(e1, v1.T):
ax.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
ax.axis([-3,3,-3,3]);
ax.set_aspect(1)
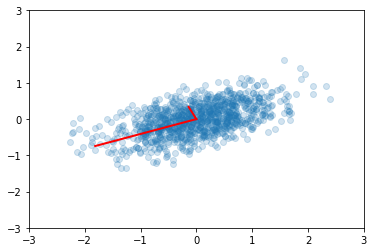
Using SVD for PCA¶
SVD is a decomposition of the data matrix \(X = U S V^T\) where \(U\) and \(V\) are orthogonal matrices and \(S\) is a diagonal matrix.
Recall that the transpose of an orthogonal matrix is also its inverse, so if we multiply on the right by \(X^T\), we get the following simplification
Compare with the eigendecomposition of a matrix \(A = W \Lambda W^{-1}\), we see that SVD gives us the eigendecomposition of the matrix \(XX^T\), which as we have just seen, is basically a scaled version of the covariance for a data matrix with zero mean, with the eigenvectors given by \(U\) and eigenvalues by \(S^2\) (scaled by \(n-1\))…
u, s, v = np.linalg.svd(x)
# reproduce previous results yet again!
e2 = s**2/(n-1)
v2 = u
plt.scatter(x[0,:], x[1,:], alpha=0.2)
for e_, v_ in zip(e2, v2):
plt.plot([0, 3*e_*v_[0]], [0, 3*e_*v_[1]], 'r-', lw=2)
plt.axis([-3,3,-3,3]);
v1 # from eigenvectors of covariance matrix
array([[ 0.925, -0.38 ],
[ 0.38 , 0.925]])
v2 # from SVD
array([[-0.925, -0.38 ],
[-0.38 , 0.925]])
e1 # from eigenvalues of covariance matrix
array([0.653, 0.121])
e2 # from SVD
array([0.653, 0.121])
Exercises: covariance matrix manipulations in Python (taken from the Duke course)¶
Given the following covariance matrix
A = np.array([[2,1],[1,4]])
use Python to do these basic tasks (that is, do not do them by hand but use scipy.linalg functions).
Show that the eigenvectors of \(A\) are orthogonal.
What is the vector representing the first principal component direction?
Find \(A^{-1}\) without performing a matrix inversion.
What are the coordinates of the data points (0, 1) and (1, 1) in the standard basis expressed as coordinates of the principal components?
What is the proportion of variance explained if we keep only the projection onto the first principal component?
We’ll give you a headstart on the Python manipulations (you should take a look at the scipy.linalg documentation).
A = np.array([[2,1],[1,4]])
eigval, eigvec = la.eig(A)
Find the matrix \(A\) that results in rotating the standard vectors in \(\mathbb{R}^2\) by 30 degrees counter-clockwise and stretches \(e_1\) by a factor of 3 and contracts \(e_2\) by a factor of \(0.5\).
What is the inverse of this matrix? How you find the inverse should reflect your understanding.
The effects of the matrix \(A\) and \(A^{-1}\) are shown in the figure below:

We observe some data points \((x_i, y_i)\), and believe that an appropriate model for the data is that
with some added noise. Find optimal values of the parameters \(\beta = (a, b, c)\) that minimize \(\Vert y - f(x) \Vert^2\)
using
scipy.linalg.lstsqsolving the normal equations \(X^TX \beta = X^Ty\)
using
scipy.linalg.svd
In each case, plot the data and fitted curve using matplotlib.
Data
x = array([ 3.4027718 , 4.29209002, 5.88176277, 6.3465969 , 7.21397852,
8.26972154, 10.27244608, 10.44703778, 10.79203455, 14.71146298])
y = array([ 25.54026428, 29.4558919 , 58.50315846, 70.24957254,
90.55155435, 100.56372833, 91.83189927, 90.41536733,
90.43103028, 23.0719842 ])
x = np.array([ 3.4027718 , 4.29209002, 5.88176277, 6.3465969 , 7.21397852,
8.26972154, 10.27244608, 10.44703778, 10.79203455, 14.71146298])
y = np.array([ 25.54026428, 29.4558919 , 58.50315846, 70.24957254,
90.55155435, 100.56372833, 91.83189927, 90.41536733,
90.43103028, 23.0719842 ])