7.2. Gaussian processes demonstration¶
Last revised: 29-Oct-2019 by Dick Furnstahl [furnstahl.1@osu.edu]
Revised: 07-Oct-2019 by Christian Forssén [christian.forssen@chalmers.se]
%matplotlib inline
import numpy as np
import scipy as sp
from scipy.stats import multivariate_normal
import matplotlib.pyplot as plt
import seaborn as sns; sns.set_style("darkgrid"); sns.set_context("talk")
import GPy # a Gaussian Process (GP) framework written in python
Gaussian processes as infinite-dimensional Gaussian distributions¶
Adapted partly from a tutorial by Andreas Damianou (2016).
A Gaussian process (GP) is a collection of random variables, any finite number of which have a joint Gaussian distribution.
Equivalently, a GP can be seen as a stochastic process which corresponds to an infinite dimensional Gaussian distribution.
Intuition by sampling and plotting multivariate Gaussians¶
Let’s first define some plotting functions that we’ll use later.
def gen_Gaussian_samples(mu, Sigma, N=200):
"""
Generate N samples from a multivariate Gaussian with mean mu
and covariance Sigma.
"""
D = mu.shape[0]
samples = np.zeros((N, D)) # N x D array
for i in np.arange(N):
samples[i,:] = np.random.multivariate_normal(mean=mu, cov=Sigma)
return samples.copy()
def gen_plot_Gaussian_samples(mu, Sigma, N=1000):
"""
Generate N samples from a multivariate Gaussian with mean mu and
covariance Sigma and plot the samples as they're generated
"""
for i in np.arange(N):
sample = np.random.multivariate_normal(mean=mu, cov=Sigma)
plt.plot(sample[0], sample[1], '.', color='r', alpha=0.6)
def plot_Gaussian_contours(x, y, mu, Sigma, N=100):
"""
Plot contours of a 2D multivariate Gaussian based on N points.
Points x and y are given for the limits of the contours.
"""
X, Y = np.meshgrid(np.linspace(x.min()-0.3, x.max()+0.3,100),
np.linspace(y.min()-0.3, y.max()+0.3,N) )
rv = multivariate_normal(mu, Sigma)
Z = rv.pdf(np.dstack((X, Y)))
plt.contour(X, Y, Z)
plt.xlabel(r'$x_1$')
plt.ylabel(r'$x_2$')
def plot_sample_dimensions(samples, colors=None, markers=None, ms=10):
"""
Given a set of samples from a bivariate Gaussian, plot them,
but instead of plotting them x1 vs x2, plot them as
[x1 x2] vs ['1', '2'].
"""
N = samples.shape[0]
D = samples.shape[1]
t=np.array(range(1,D+1))
for i in np.arange(N):
if colors is None and markers is None:
plt.plot(t,samples[i,:], '-o', ms=ms)
elif colors is None:
plt.plot(t,samples[i,:], marker=markers[i], ms=ms)
elif markers is None:
plt.plot(t,samples[i,:], '-o', color=colors[i], ms=ms)
else:
plt.plot(t,samples[i,:], color=colors[i],
marker=markers[i], ms=ms)
plt.xlim([0.8, t[-1] + 0.2])
plt.ylim([samples.min()-0.3, samples.max()+0.3])
plt.xlabel('d = {' + str(t) + '}')
plt.ylabel(r'$x_d$')
plt.gca().set_title(f'{N} samples from a bivariate Gaussian')
def set_limits(samples):
"""
Pad the limits so extend beyond minimum and maximum of samples.
"""
plt.xlim([samples[:,0].min()-0.3, samples[:,0].max()+0.3])
plt.ylim([samples[:,1].min()-0.3, samples[:,1].max()+0.3])
Review of bivariate normal case¶
\(\newcommand{\xvec}{\textbf{x}}\) \(\newcommand{\muvec}{\boldsymbol{\mu}}\) The general multivariate Gaussian distribution is
For the bivariate case we can parameterize the mean vector and covariance matrix as
The covariance matrix must be positive definite, which implies \(\color{red}{0\lt\rho^2\lt 1}\).
If take \(\mu_x = \mu_y = 0\) and \(\sigma_x = \sigma_y = \sigma\) for clarity, so that
and
It’s clear that contours of equal probability have \(x^2 + y^2 - 2\rho xy = \mbox{constant}\), so they are ellipses. The value of \(\rho\) determines the eccentricity of the ellipse. If \(\rho=0\), \(x\) and \(y\) are independent (uncorrelated) and we have a circle. As \(\rho\) approaches \(+1\), \(x\) and \(y\) are increasingly correlated (toward straight line at \(45^\circ\)), while for \(\rho\) approaching \(-1\) they become increasingly anti-correlated (toward straight line at \(-45^\circ\)).
For reference, the Cholesky decomposition of \(\Sigma\) is
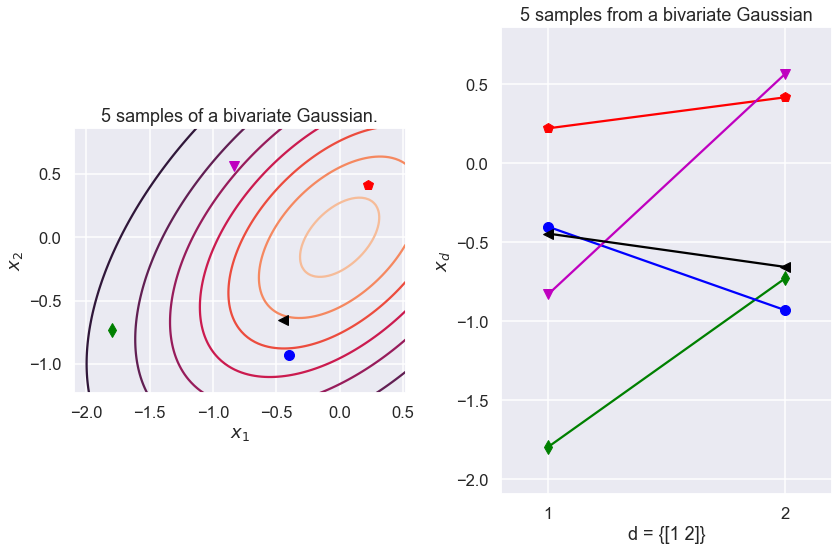
Test two different ways of plotting a bivariate Gaussian.
colors = ['r','g','b','m','k']
markers = ['p','d','o','v','<']
N = 5 # Number of samples
mu = np.array([0,0]) # Mean of the 2D Gaussian
sigma = np.array([[1, 0.5], [0.5, 1]]); # covariance of the Gaussian
# Generate samples
np.random.seed()
samples = gen_Gaussian_samples(mu, sigma, N)
fig = plt.figure(figsize=(12,8));
ax1 = plt.subplot(1, 2, 1, autoscale_on=True, aspect='equal')
#set_limits(samples)
plot_Gaussian_contours(samples[:,0], samples[:,1], mu, sigma)
# Plot samples
for i in np.arange(N):
ax1.plot(samples[i,0], samples[i,1], color=colors[i],
marker=markers[i], ms=10)
ax1.set_title(f'{N} samples of a bivariate Gaussian.')
ax2 = plt.subplot(1, 2, 2, autoscale_on=True) #, aspect='equal')
ax2.set_xticks([1,2])
plot_sample_dimensions(samples=samples, colors=colors, markers=markers)
fig.tight_layout()
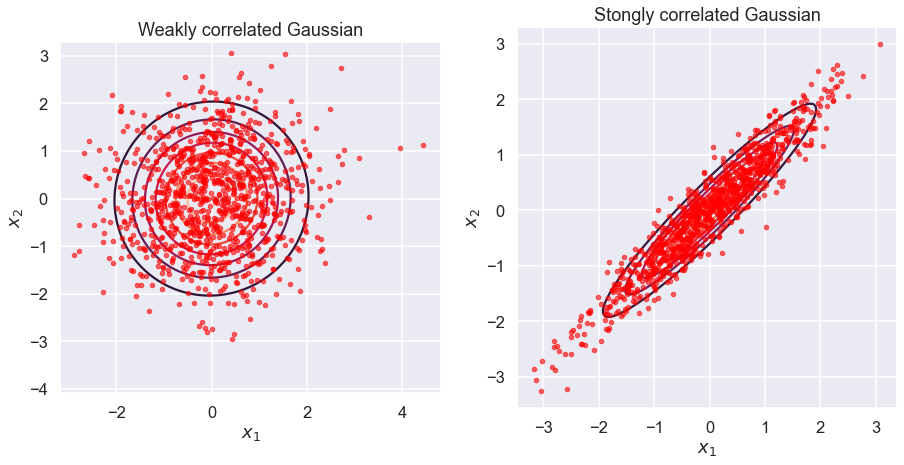
Repeat as before, but now we’ll plot many samples from two kinds of Gaussians: one with strongly correlated dimensions and one with weak correlations
# Plot with contours. Compare a correlated vs almost uncorrelated Gaussian
sigmaUncor = np.array([[1, 0.02], [0.02, 1]]);
sigmaCor = np.array([[1, 0.95], [0.95, 1]]);
f = plt.figure(figsize=(15,15));
ax = plt.subplot(1, 2, 1); ax.set_aspect('equal')
samplesUncor=gen_Gaussian_samples(mu, sigmaUncor)
plot_Gaussian_contours(samplesUncor[:,0], samplesUncor[:,1], mu, sigmaUncor)
gen_plot_Gaussian_samples(mu, sigmaUncor)
ax.set_title('Weakly correlated Gaussian')
ax=plt.subplot(1, 2, 2); ax.set_aspect('equal')
samplesCor=gen_Gaussian_samples(mu,sigmaCor)
plot_Gaussian_contours(samplesCor[:,0], samplesCor[:,1], mu, sigmaCor)
gen_plot_Gaussian_samples(mu, sigmaCor)
ax.set_title('Stongly correlated Gaussian');
But let’s plot them as before dimension-wise…
Which one is which?
f=plt.figure(figsize=(18,5));
perm = np.random.permutation(samplesUncor.shape[0])[0::14]
ax1=plt.subplot(1, 2, 2); ax1.set_aspect('auto')
plot_sample_dimensions(samplesUncor[perm,:])
ax2=plt.subplot(1, 2, 1,sharey=ax1); ax2.set_aspect('auto')
plot_sample_dimensions(samplesCor[perm,:])
if False:
ax1.set_title('Weakly correlated');
ax2.set_title('Strongly correlated')
for ax in [ax1,ax2]:
ax.set_xticks([1,2])
plt.ylim([samplesUncor.min()-0.3, samplesUncor.max()+0.3]);
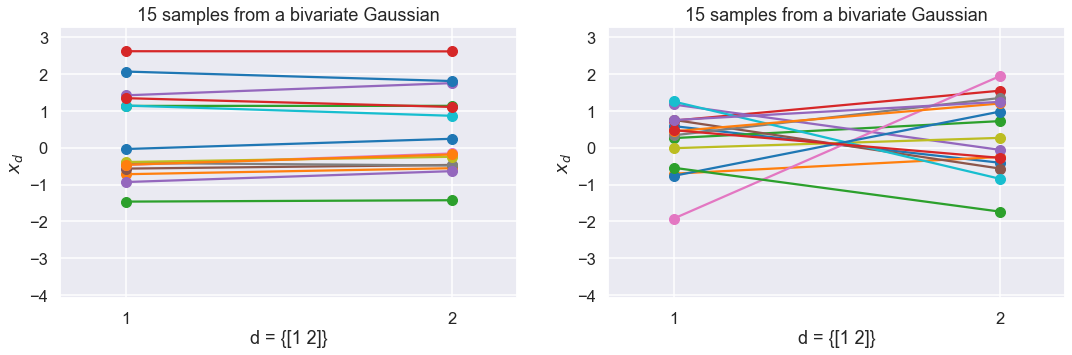
The strongly correlated Gaussian gives more “horizontal” lines in the dimension-wise plot.
More importantly, by using the dimension-wise plot, we are able to plot Gaussians which have more than two dimensions. Below we plot N samples from a D=8-dimensional Gaussian.
Because I don’t want to write down the full 8x8 covariance matrix, I define a “random” one through a mathematical procedure that is guaranteed to give me back a positive definite and symmetric matrix (i.e. a valid covariance). More on this later.
N=5
mu = np.array([0,0,0,0,0,0,0,0])
D = mu.shape[0]
# Generate random covariance matrix
x_pts = np.sort(sp.random.rand(D))[:,None]
tmp2 = x_pts**np.arange(5)
sigma = 5*np.dot(tmp2, tmp2.T) + 0.005*np.eye(D)
with np.printoptions(precision=2, suppress=True):
print('Covariance matrix:')
print(sigma)
print('Eigenvalues should be all larger than zero:')
print(np.linalg.eigvals(sigma))
# Now the samples are from a multivariate Gaussian with dimension D
samples = gen_Gaussian_samples(mu, sigma, N)
for i in np.arange(N):
plt.plot(x_pts, samples[i,:], '-o')
plt.gca().set_xlim(0., 1.)
plt.gca().set_title(f'{N} samples of a {D} dimensional Gaussian');
Covariance matrix:
[[ 5.07 5.09 5.09 5.16 5.24 5.24 5.57 5.63]
[ 5.09 5.11 5.11 5.21 5.3 5.31 5.73 5.81]
[ 5.09 5.11 5.12 5.21 5.31 5.31 5.75 5.82]
[ 5.16 5.21 5.21 5.4 5.59 5.6 6.54 6.72]
[ 5.24 5.3 5.31 5.59 5.9 5.91 7.55 7.89]
[ 5.24 5.31 5.31 5.6 5.91 5.93 7.6 7.95]
[ 5.57 5.73 5.75 6.54 7.55 7.6 15.68 17.85]
[ 5.63 5.81 5.82 6.72 7.89 7.95 17.85 20.6 ]]
Eigenvalues should be all larger than zero:
[5.69823354e+01 1.15746612e+01 2.30151690e-01 8.75735746e-03
5.02169431e-03 5.00000000e-03 5.00000000e-03 5.00000000e-03]
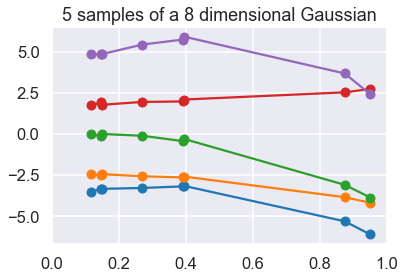
So each sample has 8 values, which we associate with the 8 x points:
print('x points: ', x_pts)
x points: [[0.11704133]
[0.14664013]
[0.1489718 ]
[0.26970668]
[0.38987859]
[0.39548656]
[0.87412383]
[0.95021217]]
Taking this even further, we can plot samples from a 200-dimensional Gaussian in the dimension-wise plot.
N=5
D=200
mu = np.zeros((D,1))[:,0]
# Generate random covariance matrix
x_pts = np.sort(sp.random.rand(D))[:,None]
tmp2 = x_pts**np.arange(5)
sigma = 5*np.dot(tmp2,tmp2.T)+ 0.0005*np.eye(D)
samples = gen_Gaussian_samples(mu,sigma,N)
for i in np.arange(N):
plt.plot(x_pts, samples[i,:], '-')
plt.gca().set_title(f'{N} samples of a {D} dimensional Gaussian');
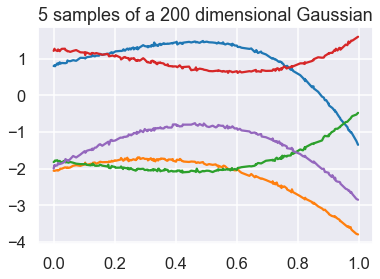
We see that each sample now starts looking like a “smooth” curve (notice that the random variables are highly correlated). Therefore, we now have a clear intuition as to why a GP can be seen as an infinite dimensional multivariate Gaussian which is used as a prior over functions, since one sample from a GP is a function.
Covariance functions, aka kernels¶
We’ll see below that the covariance function is what encodes our assumption about the GP. By selecting a covariance function, we are making implicit assumptions about the shape of the function we wish to encode with the GP, for example how smooth it is.
Even if the covariance function has a parametric form, combined with the GP it gives us a nonparametric model. In other words, the covariance function is specifying the general properties of the GP function we wish to encode, and not a specific parametric form for it.
Here we define two very common covariance functions: The RBF (also known as Exponentiated Quadratic or Gaussian kernel) which is differentiable infinitely many times (hence, very smooth),
where \(Q\) denotes the dimensionality of the input space. Its parameters are: the lengthscale \(\ell\) and the variance \(\sigma^2\).
The other covariance function is the Linear kernel: $\( k_{lin}(\mathbf{x}_{i},\mathbf{x}_{j}) = \sigma^2 \mathbf{x}_{i}^T \mathbf{x}_{j} \)$
Here are some examples with different “kernels” and different parameters that dictate those features (figure from J. Melendez):

The RBF kernel (a.k.a Gaussian)¶
def cov_RBF(x, x2=None, theta=np.array([1,1])):
"""
Compute the Euclidean distance between each row of X and X2,
or between each pair of rows of X if X2 is None and feed it
to the kernel.
The variance and lengthscale are taken to be unity if not passed.
"""
variance = theta[0]
lengthscale = theta[1]
if x2 is None:
xsq = np.sum(np.square(x),1)
r2 = -2.*np.dot(x,x.T) + (xsq[:,None] + xsq[None,:])
r = np.sqrt(r2) / lengthscale
else:
x1sq = np.sum(np.square(x),1)
x2sq = np.sum(np.square(x2),1)
r2 = -2.*np.dot(x, x2.T) + x1sq[:,None] + x2sq[None,:]
r = np.sqrt(r2) / lengthscale
return variance * np.exp(-0.5 * r**2)
Given hyperparameters \(\theta\), we plot the resulting covariance matrix and samples from a GP with this covariance function.
X = np.sort(np.random.rand(400, 1) * 6 , axis=0)
ell_rbf = [0.005, 0.1, 1, 2, 5, 12] # length scale for RBF
K = len(ell_rbf)
num_samples=5
plt.figure(figsize=(25,25))
j=1
for i in range(K):
plt.subplot(K,2,j)
K_rbf = cov_RBF(X, X, theta=np.array([1, ell_rbf[i]]))
plt.imshow(K_rbf)
plt.colorbar()
plt.gca().set_title(rf'RBF Cov. Matrix ($\ell={ell_rbf[i]}$)')
plt.subplot(K, 2, j+1)
# Assume a GP with zero mean
mu=np.zeros((1,K_rbf.shape[0]))[0,:]
for s in range(num_samples):
# Jitter is a small noise addition to the diagonal elements
# to ensure positive definiteness. Also called a nugget.
jitter = 1e-5*np.eye(K_rbf.shape[0])
sample = np.random.multivariate_normal(mean=mu, cov=K_rbf+jitter)
plt.plot(sample)
plt.gca().set_title(rf'GP Samples from RBF ($\ell={ell_rbf[i]}$)')
j+=2
plt.tight_layout()
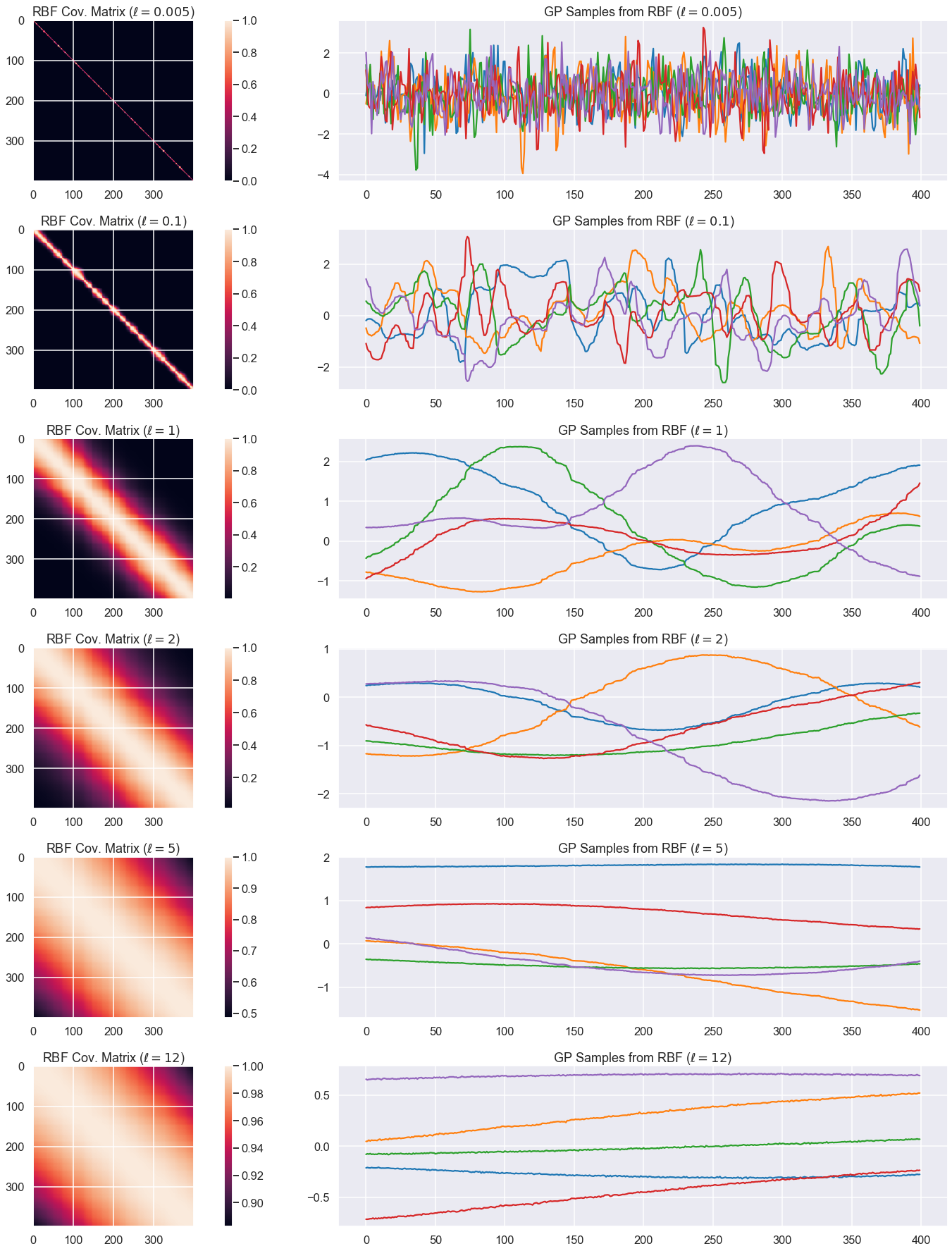
Example: GP models for regression¶
No-core shell model \(\hbar\omega\) dependence¶
# import some NCSM data from
# Phys. Rev. C 97, 034328 (2018)
(E, Nmax, hw) = np.loadtxt('Li6E_NNLOopt_Nmax10.txt', unpack=True)
fig, ax = plt.subplots(nrows=1, ncols=1)
ax.set_ylabel(r'$E$ (MeV)');
ax.set_xlabel(r'$\hbar\omega$ (MeV)');
plot_title = r'NCSM results for Li-6 energy with NNLOopt ' + \
r'at $N_\mathrm{max}=10$'
ax.set_title(plot_title)
ax.scatter(hw, E, s=10);
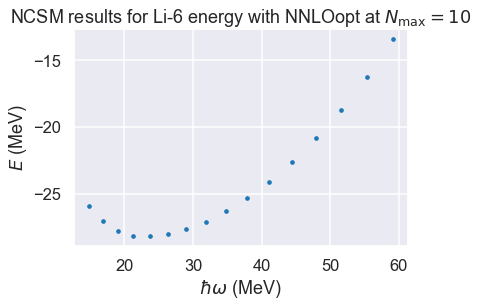
# We will test our GP by training on every third data point and validate on the rest.
# We will print the largest ratios (predict-true)/predict for the interpolate region.
ratio_min = 1.
ratio_max = 1.
x = hw
# Remove the mean and scale the data by its standard deviation.
# This defines the y values we will model with a GP.
mE = np.mean(E)
sE = np.std(E)
y = (E - mE)/sE
# Training data (xt, yt) is every 3rd point
xt = x[::3, np.newaxis]
yt = y[::3, np.newaxis]
# Define the kernel and fit the hyperparameters
kernel = GPy.kern.RBF(input_dim=1, variance=5., lengthscale=10.)
m = GPy.models.GPRegression(xt, yt, kernel)
m.optimize(messages=False)
display(m)
# Data to predict
xp = x[:, np.newaxis]
yp, vp = m.predict(xp)
for i,yi in enumerate(yp):
ratio_min=min(ratio_min,np.abs((y[i]+mE)/(yi+mE)))
ratio_max=max(ratio_max,np.abs((y[i]+mE)/(yi+mE)))
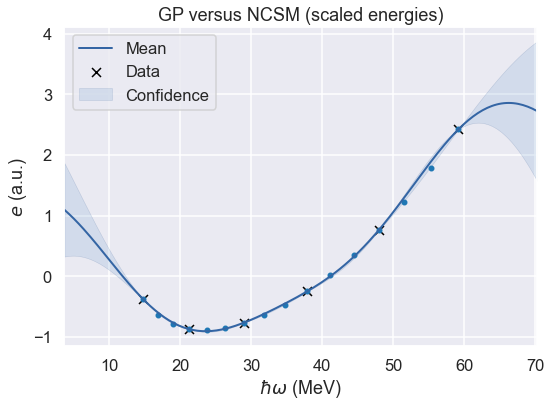
fig = m.plot(plot_density=False, figsize=(8,6))
ax=plt.gca()
ax.scatter(hw, (E-mE)/sE, s=20);
ax.set(xlabel=r'$\hbar\omega$ (MeV)', ylabel=r'${e}$ (a.u.)')
ax.set_title(r'GP versus NCSM (scaled energies)')
print(f'Validation result: Ratio true/predict in [{ratio_min[0]:8.6f}, {ratio_max[0]:8.6f}]')
Model: GP regression
Objective: 5.580147499327765
Number of Parameters: 3
Number of Optimization Parameters: 3
Updates: True
| GP_regression. | value | constraints | priors |
|---|---|---|---|
| rbf.variance | 2.7334831243366655 | +ve | |
| rbf.lengthscale | 15.493754387168465 | +ve | |
| Gaussian_noise.variance | 3.9116924072201616e-10 | +ve |
Validation result: Ratio true/predict in [0.998527, 1.004752]