6.6. PyMC3 Introduction¶
Last revised 25-Oct-2021 by Dick Furnstahl (furnstahl.1@osu.edu)
A good starting point for notebooks with PyMC3 examples is the official documentation site: https://docs.pymc.io/. We’ve adapted some examples from that site here and in other notebooks.
Aside. Here is a good quote from Rob Hicks on HMC and No U-Turn:
“The idea: rather than blindly stumbling around the posterior, use the posterior gradient to skate around the gradient contour. As you skate closer to a drop-off (gradient is steep and probability is lower), potential energy decreases and kinetic energy increases (since energy is always conserved). When this happens the skater is turned back uphill and pushed from the precipice and skates on along a posterior likelihood contour. The No U-Turn sampler keeps skating until the skater tries to turn back towards the original point.”
Imports¶
import numpy as np
import scipy.stats as stats
import arviz as az
import matplotlib.pyplot as plt
import pymc3 as pm
# Recommended: document what PyMC3 version we are using
print(f'Running on PyMC3 v{pm.__version__}')
Running on PyMC3 v3.11.2
Basic setup of a model¶
First we need to create a model, which will be an instance of the Model class. The model has references to all random variables (RVs) and computes the model log posterior (logp) and its gradients. We typically instantiate it using a with context. For example:
with pm.Model() as my_model:
mu = pm.Normal('mu', mu=0, sigma=1)
obs = pm.Normal('obs', mu=mu, sigma=1, observed=np.random.randn(100))
So my_model is an instance of the PyMC3 Model class, and we have set up a prior for mu in the form of a standard normal distribution (i.e., mean = 0 and standard deviation = 1). The last line sets up the likelihood, also distributed as a normal with observed data taken as 100 random draws from a standard normal distribution. The standard deviation sigma for the mu posterior is given. The goal will be to sample the posterior for mu.
Sampling¶
The main entry point to MCMC sampling algorithms is via the pm.sample() function. By default, this function tries to auto-assign the right sampler(s) and auto-initialize if you don’t pass anything.
As you can see, on a continuous model, PyMC3 assigns the NUTS sampler, which is very efficient even for complex models. PyMC3 also runs variational inference (i.e. ADVI) to find good starting parameters for the sampler. Here we draw 1000 samples from the posterior and allow the sampler to adjust its parameters in an additional 500 iterations. These 500 samples are discarded by default:
with pm.Model() as my_NUTS_model:
avg = pm.Normal('avg', mu=0, sigma=1)
model = avg
obs = pm.Normal('obs', mu=model, sigma=1, observed=np.random.randn(100))
trace_NUTS = pm.sample(1000, tune=1000, return_inferencedata=False)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [avg]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 15 seconds.
with my_NUTS_model:
az.plot_trace(trace_NUTS);

Available samplers¶
PyMC3 offers a variety of samplers, found in pm.step_methods:
list(filter(lambda x: x[0].isupper(), dir(pm.step_methods)))
['BinaryGibbsMetropolis',
'BinaryMetropolis',
'CategoricalGibbsMetropolis',
'CauchyProposal',
'CompoundStep',
'DEMetropolis',
'DEMetropolisZ',
'DEMetropolisZMLDA',
'ElemwiseCategorical',
'EllipticalSlice',
'HamiltonianMC',
'LaplaceProposal',
'MLDA',
'Metropolis',
'MetropolisMLDA',
'MultivariateNormalProposal',
'NUTS',
'NormalProposal',
'PGBART',
'PoissonProposal',
'RecursiveDAProposal',
'Slice',
'UniformProposal']
Commonly used step-methods besides NUTS include Metropolis and Slice. The claim is that for almost all continuous models, NUTS should be preferred. There are hard-to-sample models for which NUTS will be very slow causing many users to use Metropolis instead. This practice, however, is rarely successful. NUTS is fast on simple models but can be slow if the model is very complex or it is badly initialized. In the case of a complex model that is hard for NUTS, Metropolis, while faster, will have a very low effective sample size or not converge properly at all. A better approach is to instead try to improve initialization of NUTS, or reparameterize the model.
For completeness, other sampling methods can be passed to sample. Here is an example (Metropolis-Hastings):
with pm.Model() as my_Metropolis_model:
mu = pm.Normal('mu', mu=0, sigma=1)
obs = pm.Normal('obs', mu=mu, sigma=1, observed=np.random.randn(100))
step = pm.Metropolis()
trace_MH = pm.sample(1000, step=step, return_inferencedata=False)
az.plot_trace(trace_MH);
Multiprocess sampling (4 chains in 4 jobs)
Metropolis: [mu]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 13 seconds.
The number of effective samples is smaller than 25% for some parameters.

Analyze sampling results¶
The most common used plot to analyze sampling results is the so-called trace-plot, now invoked with a arViz plot_trace command:
with my_NUTS_model:
az.plot_trace(trace_NUTS);
#pm.traceplot(trace_NUTS);

with pm.Model() as model:
mu = pm.Normal('mu', mu=0, sd=1)
sd = pm.HalfNormal('sd', sd=1)
obs = pm.Normal('obs', mu=mu, sd=sd, observed=np.random.randn(100))
step1 = pm.Metropolis(vars=[mu])
step2 = pm.Slice(vars=[sd])
trace_2_samplers = pm.sample(10000, step=[step1, step2], cores=4,
return_inferencedata=False)
az.plot_trace(trace_2_samplers);
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>Metropolis: [mu]
>Slice: [sd]
Sampling 4 chains for 1_000 tune and 10_000 draw iterations (4_000 + 40_000 draws total) took 21 seconds.
The number of effective samples is smaller than 25% for some parameters.
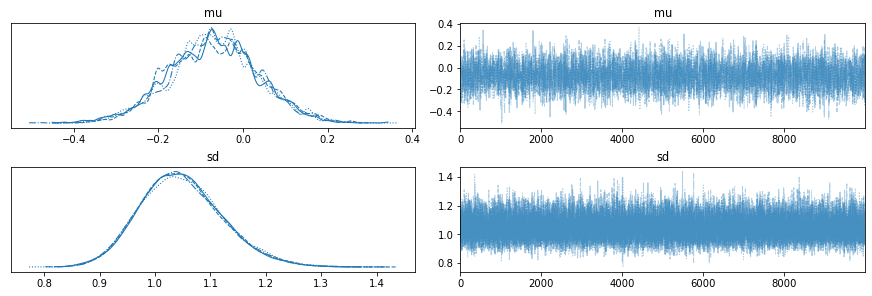
Diagnostics¶
with pm.Model() as model:
display(az.summary(trace_2_samplers))
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| mu | -0.070 | 0.105 | -0.273 | 0.123 | 0.001 | 0.001 | 5750.0 | 6274.0 | 1.0 |
| sd | 1.048 | 0.075 | 0.915 | 1.194 | 0.000 | 0.000 | 35645.0 | 27953.0 | 1.0 |
with my_Metropolis_model:
display(az.summary(trace_MH))
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
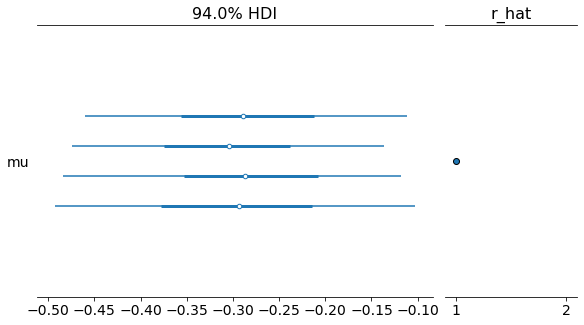
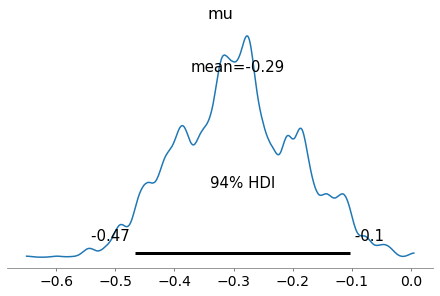
| mu | -0.292 | 0.101 | -0.467 | -0.103 | 0.004 | 0.003 | 570.0 | 532.0 | 1.0 |
with my_Metropolis_model:
az.plot_forest(trace_MH, r_hat=True);
with pm.Model() as my_Metropolis_model:
pm.plot_posterior(trace_MH);
Examples from Rob Hicks¶
See https://rlhick.people.wm.edu/stories/bayesian_7.html. We also have a notebook from his Bayesian 8 “story”.
We start with a very simple one parameter model and then move to slightly more complicated settings:
sigma = 3. # standard deviation
mu = 10. # mean
num_samples = 100 # 10**6
# sample from a normal distribution
data = stats.norm(mu, sigma).rvs(num_samples)
# plot a histogram of the sampled data
num_bins = 20
plt.hist(data, bins=num_bins)
plt.show()
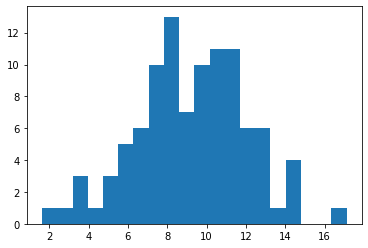
Run the previous cell a few times to see the fluctuations. Crank up the number of samples to 10**6 to see a smoother histogram.
PyMC3 implementation¶
We instantiate a Model with a descriptions of priors and the likelihood. Here, mu is defined to be a random variable (we want to sample this variable by generating a Markov chain) and we provide a prior distribution with associated hyper-parameters for it. The likelihood function is chosen to be Normal, with one parameter to be estimated (mu), and we use known \(\sigma\) (denoted as sigma). Our “dependent variable” is given by observed=data, where data is generated above and shown in the histogram. So we our implementing Bayes theorem in the form:
# parameters for the prior on mu
mu_prior = 8.
sigma_prior = 1.5 # Note this is our prior on the std of mu
# Could do this instead as:
# basic_model = pm3.Model()
# with basic_model:
with pm.Model() as basic_model:
# Prior for unknown model parameters (mean and sd of the normal pdf)
mu = pm.Normal('Mean of Data', mu_prior, sigma_prior)
# Likelihood (sampling distribution) of observations
data_in = pm.Normal('Y_obs', mu=mu, sigma=sigma, observed=data)
Next we define how the Markov chain will be constructed. The example we are following set startvals to be the MAP and used a Metropolis step method. There always seems to be a complaint with the latest pyMC3 about using find_MAP to start the sampler.
chain_length = 10000
with basic_model:
# obtain starting values via MAP (maximum a posteriori)
startvals = pm.find_MAP(model=basic_model) # model here is optional
print(startvals)
# instantiate sampler
step = pm.Metropolis() # Metropolis-Hastings
# draw 10000 posterior samples for each chain (4 chains by default?)
trace = pm.sample(draws=chain_length, step=step, start=startvals,
return_inferencedata=False)
{'Mean of Data': array(9.18219456)}
Multiprocess sampling (4 chains in 4 jobs)
Metropolis: [Mean of Data]
Sampling 4 chains for 1_000 tune and 10_000 draw iterations (4_000 + 40_000 draws total) took 17 seconds.
The number of effective samples is smaller than 25% for some parameters.
# Plot the four chains
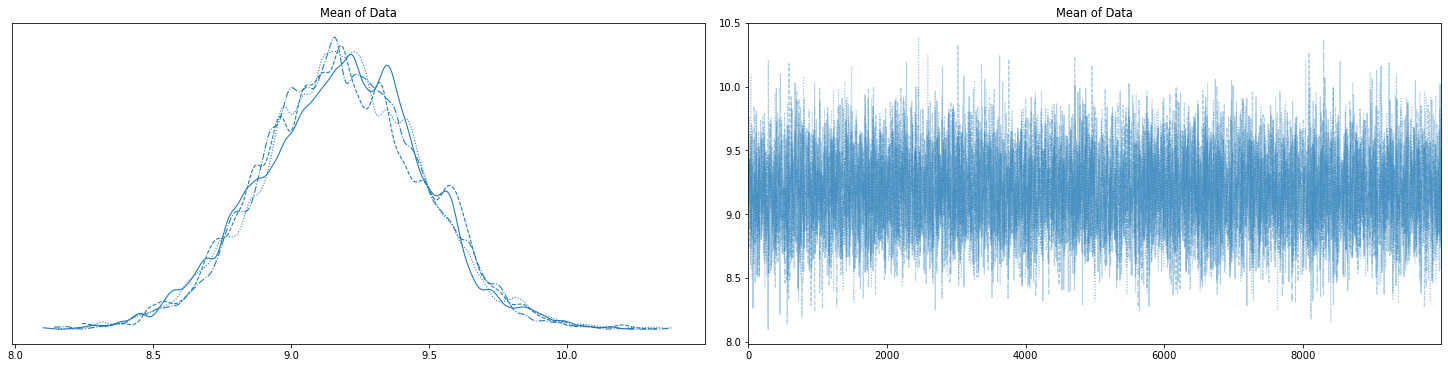
with basic_model:
az.plot_trace(trace, figsize=(20,5));
# Summary information on the Markov chains
with basic_model:
display(az.summary(trace))
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Mean of Data | 9.182 | 0.293 | 8.619 | 9.712 | 0.003 | 0.002 | 8392.0 | 8526.0 | 1.0 |
Remember that what we are generating is a posterior for the mean given the data and our (assumed) knowledge of the standard deviation.
So for the summary info we get the mean and standard deviation (sd) of the distribution, with an estimate of the Monte Carlo error. What does hpd stand for? “Highest posterior density” 2.5 and 97.5 are percentages, so one talks of a 95% hpd interval in this case.
From an answer online: “You create the parameter trace plots to make sure that your a priori distribution is well calibrated which is indicated by your parameters having sufficient state changes as the MCMC algorithm runs.”
“All the results are contained in the trace variable. This is a pymc3 results object. It contains some information that we might want to extract at times. Varnames tells us all the variable names setup in our model.”
with basic_model:
display(trace.varnames)
['Mean of Data']
This was set up when we initiated our model (in specifying the prior for mu). With the variable names, we can extract chain values for each variable:
trace['Mean of Data']
array([9.03501439, 9.03501439, 9.03501439, ..., 9.44669237, 9.53682737,
9.53682737])
Is this one chain or all four chains? Check the length! Looks like all four.
print(len(trace['Mean of Data']))
print(trace['Mean of Data'].shape)
40000
(40000,)
Now for diagnostics.
Autocorrelation plots¶
with basic_model:
az.plot_autocorr(trace, figsize=(17,5));
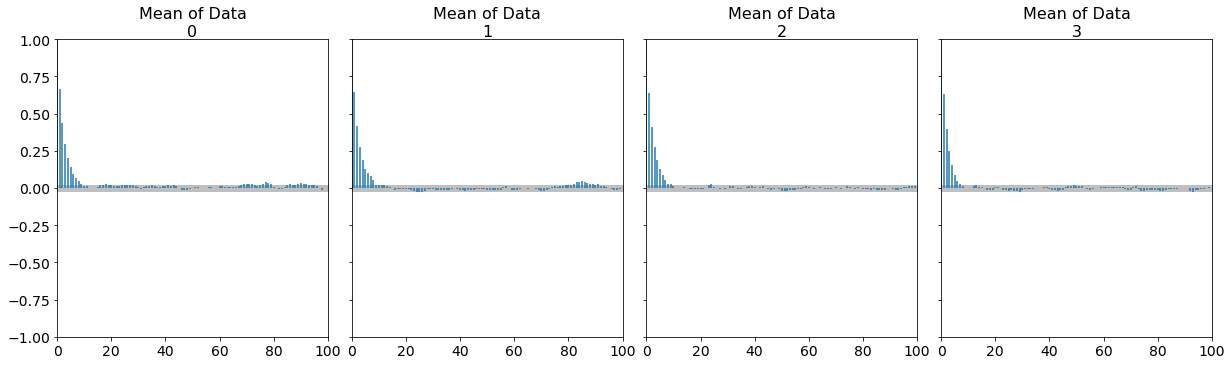
What do we see here? An autocorrelation time around 10 or so.
Acceptance rate¶
accept = np.sum(trace['Mean of Data'][1:] != trace['Mean of Data'][:-1])
print("Acceptance Rate: ", accept/trace['Mean of Data'].shape[0])
Acceptance Rate: 0.333075
That looks like we have to work harder than one might have expected. It is taking the array of results and comparing each point to the previous one and including it in the sum if it is different. So if there wasn’t an acceptance, then the point remains the same. The ratio to the full length is the acceptance rate. Maybe we should define a function here instead.
def acceptance_rate(trace_array):
"""Calculate how many times the entry in the trace array changed compared
to the total length.
"""
changed = np.sum(trace_array[1:] != trace_array[:-1])
total_length = trace_array.shape[0]
return changed / total_length
acceptance_rate(trace['Mean of Data'])
0.333075
InferenceData object¶
# parameters for the prior on mu
mu_prior = 8.
sigma_prior = 1.5 # Note this is our prior on the std of mu
# Could do this instead as:
# basic_model = pm3.Model()
# with basic_model:
with pm.Model() as basic_model_alt:
# Prior for unknown model parameters (mean and sd of the normal pdf)
mu = pm.Normal('Mean of Data', mu_prior, sigma_prior)
# Likelihood (sampling distribution) of observations
data_in = pm.Normal('Y_obs', mu=mu, sigma=sigma, observed=data)
chain_length = 10000
with basic_model_alt:
# obtain starting values via MAP (maximum a posteriori)
startvals = pm.find_MAP(model=basic_model) # model here is optional
print(startvals)
# instantiate sampler
step = pm.Metropolis() # Metropolis-Hastings
# draw 10000 posterior samples for each chain (4 chains by default?)
trace_inferencedata = pm.sample(draws=chain_length, step=step, start=startvals,
return_inferencedata=True)
{'Mean of Data': array(9.18219456)}
Multiprocess sampling (4 chains in 4 jobs)
Metropolis: [Mean of Data]
Sampling 4 chains for 1_000 tune and 10_000 draw iterations (4_000 + 40_000 draws total) took 17 seconds.
The number of effective samples is smaller than 25% for some parameters.
with basic_model_alt:
display(trace_inferencedata.sample_stats)
<xarray.Dataset>
Dimensions: (chain: 4, draw: 10000)
Coordinates:
* chain (chain) int64 0 1 2 3
* draw (draw) int64 0 1 2 3 4 5 6 ... 9993 9994 9995 9996 9997 9998 9999
Data variables:
accepted (chain, draw) bool True False True False ... False False True
accept (chain, draw) float64 1.235 4.306e-05 0.7832 ... 0.5771 1.011
scaling (chain, draw) float64 1.0 1.0 1.0 1.0 1.0 ... 1.0 1.0 1.0 1.0 1.0
Attributes:
created_at: 2021-11-02T13:45:06.402177
arviz_version: 0.11.2
inference_library: pymc3
inference_library_version: 3.11.2
sampling_time: 17.16851305961609
tuning_steps: 1000- chain: 4
- draw: 10000
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 ... 9996 9997 9998 9999
array([ 0, 1, 2, ..., 9997, 9998, 9999])
- accepted(chain, draw)boolTrue False True ... False True
array([[ True, False, True, ..., False, False, False], [False, False, False, ..., False, False, True], [ True, False, False, ..., False, True, True], [False, True, False, ..., False, False, True]]) - accept(chain, draw)float641.235 4.306e-05 ... 0.5771 1.011
array([[1.23457838e+00, 4.30591498e-05, 7.83221228e-01, ..., 2.50866135e-02, 1.42092133e-07, 2.21195296e-01], [6.63223936e-03, 3.74724048e-01, 3.98321809e-03, ..., 2.44893114e-01, 8.42743363e-05, 9.89706179e-01], [1.17706304e+00, 8.25555962e-01, 1.04221793e-03, ..., 1.31197355e-03, 4.68911323e-01, 1.72878035e+00], [1.19617218e-06, 1.11834138e+01, 1.29300305e-01, ..., 1.84807344e-10, 5.77117668e-01, 1.01102982e+00]]) - scaling(chain, draw)float641.0 1.0 1.0 1.0 ... 1.0 1.0 1.0 1.0
array([[1., 1., 1., ..., 1., 1., 1.], [1., 1., 1., ..., 1., 1., 1.], [1., 1., 1., ..., 1., 1., 1.], [1., 1., 1., ..., 1., 1., 1.]])
- created_at :
- 2021-11-02T13:45:06.402177
- arviz_version :
- 0.11.2
- inference_library :
- pymc3
- inference_library_version :
- 3.11.2
- sampling_time :
- 17.16851305961609
- tuning_steps :
- 1000
Gelman Rubin Diagnostic (quoted verbatim from the Hicks notebook)¶
If our MH MCMC Chain reaches a stationary distribution, and we repeat the excercise multiple times, then we can examine if the posterior for each chain converges to the same place in the distribution of the parameter space.
Steps:
Run \(M>1\) Chains of length \(2 \times N\).
Discard the first \(N\) draws of each chain, leaving \(N\) iterations in the chain.
Calculate the within and between chain variance.
Within chain variance: \(W = \frac{1}{M}\sum_{j=1}^M s_j^2 \) where \(s_j^2\) is the variance of each chain (after throwing out the first \(N\) draws).
Between chain variance: \(B = \frac{N}{M-1} \sum_{j=1}^M (\bar{\theta_j} - \bar{\bar{\theta}})^2\) where \(\bar{\bar{\theta}}\) is the mean of each of the M means.
Calculate the estimated variance of \(\theta\) as the weighted sum of between and within chain variance. \(\hat{var}(\theta) = \left ( 1 - \frac{1}{N}\right ) W + \frac{1}{N}B\)
Calculate the potential scale reduction factor. \(\hat{R} = \sqrt{\frac{\hat{var}(\theta)}{W}}\)
We want this number to be close to 1. Why? This would indicate that the between chain variance is small. This makes sense, if between chain variance is small, that means both chains are mixing around the stationary distribution. Gelmen and Rubin show that when \(\hat{R}\) is greater than 1.1 or 1.2, we need longer burn-in.
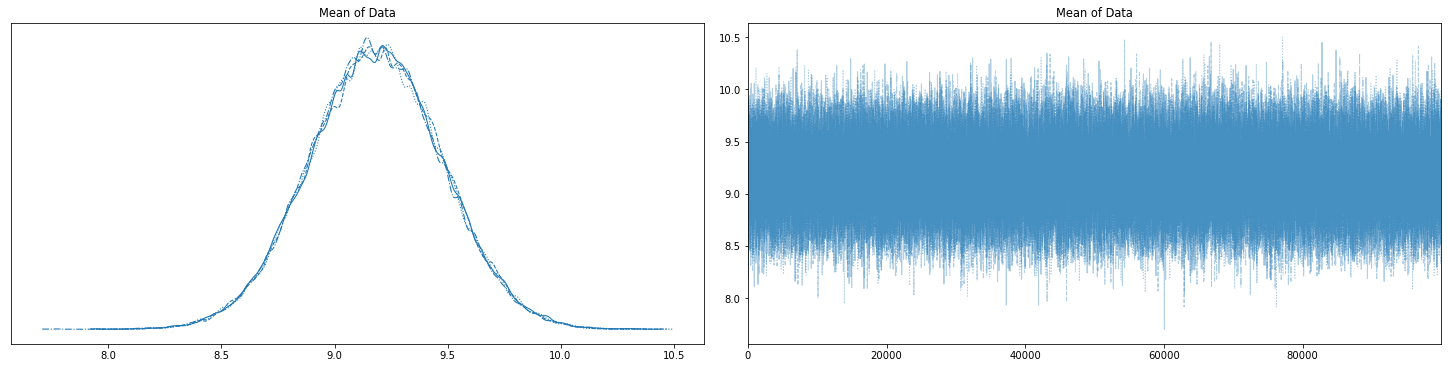
Trying without find_MAP, i.e., not specifying start in pm.sample.
chain_length = 100000
with basic_model:
# obtain starting values via MAP
#startvals = pm.find_MAP(model=basic_model)
#print(startvals)
# instantiate sampler
step = pm.Metropolis()
# draw 5000 posterior samples
trace = pm.sample(chain_length, step=step, return_inferencedata=False)
Multiprocess sampling (4 chains in 4 jobs)
Metropolis: [Mean of Data]
Sampling 4 chains for 1_000 tune and 100_000 draw iterations (4_000 + 400_000 draws total) took 58 seconds.
The number of effective samples is smaller than 25% for some parameters.
# Plot the four chains
with basic_model:
az.plot_trace(trace, figsize=(20,5));
“The diagnostics we have discussed are all univariate (they work perfectly when there is only 1 parameter to estimate). Other diagnostics have been derived for the multivariate case, but these are useful only when using Gibbs Samplers or other specialized versions of Metropolis-Hastings.
So most people examine univariate diagnostics for each variable, examine autocorrelation plots, acceptance rates and try to argue chain convergence based on that- unless they are using Gibbs or other specialized samplers.”
In-class exercise¶
Let’s try to modify the code below to estimate sigma as well as the mean:
sigma = 3. # standard deviation
mu = 10. # mean
num_samples = 100 # 10**6
# sample from a normal distribution
data = stats.norm(mu, sigma).rvs(num_samples)
# plot a histogram of the sampled data
num_bins = 20
plt.hist(data, bins=num_bins)
plt.show()
# parameters for the prior on mu
mu_mean_prior = 8.
mu_sd_prior = 1.5 # Note this is our prior on the std of mu
with pm.Model() as basic_model:
# Priors for unknown model parameters
mu = pm.Normal('Mean of Data', mu_mean_prior, mu_sd_prior)
# Likelihood (sampling distribution) of observations
data_in = pm.Normal('Y_obs', mu=mu, sd=sigma, observed=data)
chain_length = 10000
with basic_model:
# obtain starting values via MAP
startvals = pm.find_MAP(model=basic_model)
print(startvals)
# instantiate sampler
step = pm.Metropolis()
# draw 10000 posterior samples
trace = pm.sample(chain_length, step=step, start=startvals,
return_inferencedata=False)
{'Mean of Data': array(9.80290807)}
Multiprocess sampling (4 chains in 4 jobs)
Metropolis: [Mean of Data]
Sampling 4 chains for 1_000 tune and 10_000 draw iterations (4_000 + 40_000 draws total) took 17 seconds.
The number of effective samples is smaller than 25% for some parameters.
# NOTE: currently there is an issue with geweke. Try again in the future.
# score=pm.geweke(trace, first=0.1, last=0.5, intervals=20)
# plt.scatter(score[0]['Mean of Data'][:,0],score[0]['Mean of Data'][:,1],
# marker = 'o', s=100)
# plt.axhline(-1.98, c='r')
# plt.axhline(1.98, c='r')
# plt.ylim(-2.5,2.5)
# plt.xlim(0-10,.5*trace['Mean of Data'].shape[0]/2+10)
# my_title = 'Geweke Plot Comparing first 10% and Slices of the Last 50%' +\
# ' of Chain\nDifference in Mean Z score'
# plt.title(my_title)
# plt.show()
Ok, we’re trying it!
sigma = 3. # standard deviation
mu = 10. # mean
num_samples = 1000 # 100 # 10**6
# sample from a normal distribution
data = stats.norm(mu, sigma).rvs(num_samples)
# plot a histogram of the sampled data
num_bins = 20
plt.hist(data, bins=num_bins)
plt.show()
# parameters for the prior on mu
mu_mean_prior = 8.
mu_sd_prior = 1.5 # Note this is our prior on the std of mu
sigma_mean_prior = 1.
sigma_sd_prior = 1.
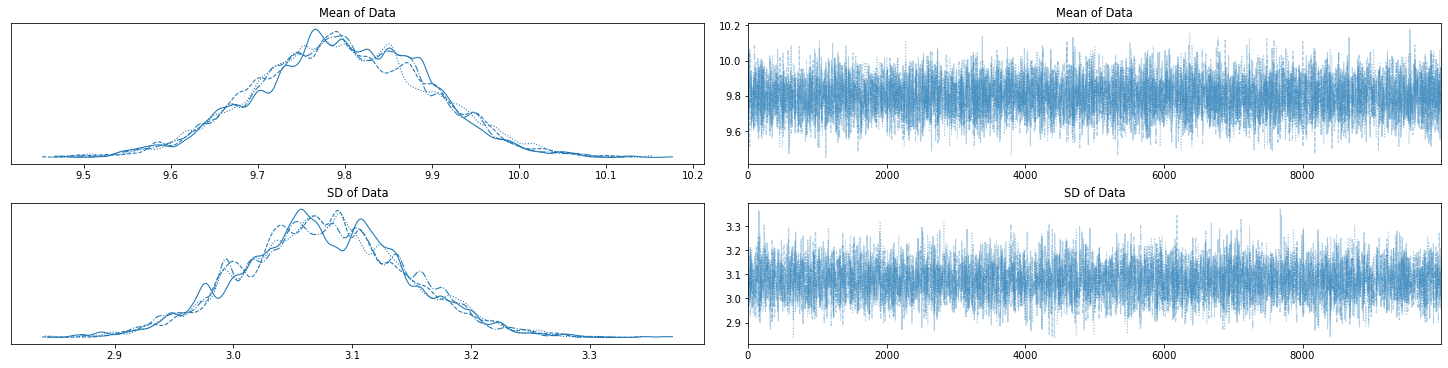
with pm.Model() as two_param_model:
# Priors for unknown model parameters
mu = pm.Normal('Mean of Data', mu_mean_prior, mu_sd_prior)
sigma = pm.Normal('SD of Data', sigma_mean_prior, sigma_sd_prior)
# Likelihood (sampling distribution) of observations
data_in = pm.Normal('Y_obs', mu=mu, sd=sigma, observed=data)
chain_length = 10000
with two_param_model:
# obtain starting values via MAP
startvals = pm.find_MAP(model=two_param_model)
print(startvals)
# instantiate sampler
step = pm.Metropolis()
# draw 10000 posterior samples
trace_two_param = pm.sample(chain_length, step=step, start=startvals,
return_inferencedata=False)
{'Mean of Data': array(9.79857562), 'SD of Data': array(3.07065777)}
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>Metropolis: [SD of Data]
>Metropolis: [Mean of Data]
Sampling 4 chains for 1_000 tune and 10_000 draw iterations (4_000 + 40_000 draws total) took 19 seconds.
The number of effective samples is smaller than 25% for some parameters.
with two_param_model:
az.plot_trace(trace_two_param, figsize=(20,5));
# NOTE: currently there is an issue with geweke. Try again in the future.
# score=pm.geweke(trace_two_param, first=0.1, last=0.5, intervals=20)
# plt.scatter(score[0]['Mean of Data'][:,0],score[0]['Mean of Data'][:,1],
# marker = 'o', s=100)
# plt.axhline(-1.98, c='r')
# plt.axhline(1.98, c='r')
# plt.ylim(-2.5,2.5)
# plt.xlim(0-10,.5*trace['Mean of Data'].shape[0]/2+10)
# my_title = 'Geweke Plot Comparing first 10% and Slices of the Last 50%' +\
# ' of Chain\nDifference in Mean Z score'
# plt.title(my_title)
# plt.show()
# NOTE: currently there is an issue with geweke. Try again in the future.
# score=pm.geweke(trace_two_param, first=0.1, last=0.5, intervals=20)
# plt.scatter(score[0]['SD of Data'][:,0],score[0]['SD of Data'][:,1], marker = 'o', s=100)
# plt.axhline(-1.98, c='r')
# plt.axhline(1.98, c='r')
# plt.ylim(-2.5,2.5)
# #plt.xlim(0-10,.5*trace['SD of Data'].shape[0]/2+10)
# plt.title('Geweke Plot Comparing first 10% and Slices of the Last 50% of Chain\nDifference in SD Z score')
# plt.show()