Path integrals for quantum mechanics: using emcee
Contents
Path integrals for quantum mechanics: using emcee#
The original reference here is Peter Lepage’s lectures entitled Lattice QCD for Novices, available as arXiv:hep-lat/0506036. The starting point of those lectures is one-dimensional quantum mechanics and that is where we focus our attention. The aim is to implement the calculations outlined by Lepage but using a standard libraries for Markov Chain Monte Carlo (MCMC) designed for Bayesian inference (called emcee).
To preview where we are going, the basic idea is that we can think of a discretized path in imaginary time \(x(\tau)\rightarrow \{x(\tau_0), x(\tau_1), \ldots, x(\tau_{N-1})\}\) as a set of \(N\) parameters and the path integral weighting factor \(e^{-S[x(\tau)]}\) as an unnormalized probability density function (or pdf, called the likelihood). We’ll multiply this with a uniform prior pdf to make a posterior pdf. If we sample the posterior with MCMC methods, we are sampling the paths according to the weighting by the action. Then we can use the samples to take quantum mechanical expectation values.
Python packages needed:
emcee (
conda install -c astropy emcee)corner (
conda install -c astropy corner) # Probably installed with emceeZeus (
conda install -c conda-forge zeus-mcmc)
Path integral basics#
Formal aspects#
We start with a path integral representation for an imaginary-time evolution between position eigenstates in one spatial dimension (here we use units where \(\hbar = 1\)):
where \(\tau = it\) and
The Hamiltonian is \(\widehat H\) and \(S[x(\tau)]\) is the classical action evaluated for path \(x(\tau)\):
This is the Euclidean version of \(S\) and the Lagrangian \(L\), which is why the relative sign of the kinetic and potential terms is positive (i.e., \(L = T_E + V\) rather than \(L = T - V\)).
If we insert on the left side of the matrix element above a complete set of exact eigenstates of \(\widehat H\) (labeled by \(n\)), namely
then we can use \(e^{-\widehat H (\tau_f - \tau_i)}|E_n\rangle = e^{-E_n(\tau_f-\tau_i)}|E_n\rangle\) (which follows after a power series expansion of the exponential) to obtain
which involves both the wave functions and energy eigenvalues. Because \(E_0 < E_{n\neq 0}\), we can take \(T \equiv \tau_f - \tau_i \rightarrow \infty\) to isolate the first terms (all the others are suppressed exponentially relative to the first). We have the freedom to take \(x_f = x_i \equiv x\), which yields in the large time limit:
The wavefunction \(\psi_{E_0}(x) = \langle x|E_0\rangle\) is normalized, so
and we get the energy (then we can go back and divide out this factor to get the wave function squared).
To derive the path integral formally, we divide up the Euclidean time interval from \(\tau_i\) to \(\tau_f\) into little intervals of width \(\Delta \tau\) (called \(\varepsilon\) in other notes) and insert a complete set of \(x\) states at each time. This enables us to approximate \(e^{-\widehat H\Delta\tau}\) in each interval. In a full derivation we would insert both momentum and coordinate states and evaluate the matrix element of \(\widehat H(\hat p,\hat x)\). The small \(\Delta\tau\) lets us neglect the commutator between \(\hat p\) and \(\hat x\) as higher order (proportional to \(\Delta\tau^2\)) If we then do all the momentum integrals, we get the path integral over \(\mathcal{D}x(\tau)\).
Numerical implementation#
In the formal discussion of path integrals, a path is defined at every continuous point in Euclidan time \(\tau\), but to represent this on a computer (and actually make a sensible definition), we discretize the time:
with grid (mesh) spacing \(a\):
A path is then a list of numbers:
and the integration over all paths becomes a conventional multiple integral over the values of \(x_j\) at each \(\tau_j\) for \(1 \leq j \leq N-1\):
The endpoints \(x_0\) and \(x_N\) are determined by the boundary conditions (e.g., \(x_0 = x_N = x\) as used above). If we need the normalization \(A\) (which we often won’t because it will drop out of ratios), then for the one-dimensional problems here it is
We will need an approximation to the action. Here is one choice for \(\tau_{j} \leq \tau \leq \tau_{j+1}\):
Now we have
where
with \(x_0 = x_N = x\) and \(a = T/N\).
Comments:
One might worry about the discretization of the derivatives, because of the range of the \(x_{j}\)’s: adjacent points can be arbitrarily far away (the paths can be arbitrarily “rough”).
Other matrix elements#
Suppose we wanted a Euclidean expectation value:
where there is an integration over \(x_i = x_f = x\) as well as over the intermediate \(x(t)\)’s. Note that we are calculating a weighted average of \(x(\tau_2)x(\tau_1)\) over all paths, where the weighting factor is \(e^{-S[x]}\). This means that for every path, we take the values of \(x\) at \(\tau_2\) and \(\tau_1\) and multiply them together, with the weight \(e^{-S[x]}\) that involves the entire path.
In the continuum form, the right side is
so with \(T = \tau_f - \tau_i\) and \(\tau = \tau_2 - \tau_1\), we can insert our complete set of eigenstates to derive
Once again, for large \(T\) the ground state will dominate the sums, so
But what state propagates in the middle? It could be any created by \(\hat x\) acting on the ground state. But this doesn’t include the ground state because \(\hat x\) switches the parity of the state (from even to odd). We can insert a complete set of states again, and if \(\tau \ll T\) is large itself, then the first excited state \(|E_1\rangle\) will be projected out:
Given \(G(\tau)\), we can use the \(\tau\) dependence of the exponential (and \(\tau\) independence of the squared matrix element) to isolate the excitation energy and then the matrix element:
We can, in principle, generalize to an arbitrary function of \(x\), call it \(\Gamma[x]\), and compute any physical property of the excited states. We can also compute thermal averages at finite \(T\):
Numerical evaluation with MCMC#
The idea of the Monte Carlo evaluation of
is that this is a weighted average of \(\Gamma[x]\) over paths, so if we generate a set of paths that are distributed according to \(e^{-S[x]}\) considered as a probability density function (that is, the relative probability of a given path is proportional to this factor), then we can just do a direct average of \(\Gamma[x]\) over this set.
To be explicit, we will generate a large number \(N_{\rm cf}\) of random paths (“configurations” or cf)
on the time grid such that the probability of getting a particular path \(x^{(\alpha)}\) is
Then
This is equivalent to approximating the probability distribution as
where the delta function is the product of delta functions for each of the \(x_j\)’s. Note that this representation is automatically normalized simply by including the \(1/N_{\rm cf}\) factor.
How good is the estimate? With a finite number of paths \(N_{\rm cf}\) there is clearly a statistical error \(\sigma_{\overline\Gamma}\), which he can estimate by calculating the variance using are set of paths:
The numerator for large \(N_{\rm cf}\) is independent of \(N_{\rm cf}\) (e.g., it can be calculated directly, in principle, from quantum mechanics), so the error decreases as \(\sigma_{\overline\Gamma} \propto 1/\sqrt{N_{\rm cf}}\) with increasing \(N_{\rm cf}\).
We can use Markov Chain Monte Carlo (MCMC) to generate our sample of paths, either by implementing the Metropolis algorithm ourselves or by adapting to this use the sophisticated packages used for Bayesian statistical analysis. Starting from an arbitrary path \(x^{(0)}\), we generate a series of subsequent paths by considering each lattice site in turn, randomizing the \(x_j\)’s at these sites according to the algorithm, to generate a new path, and then repeat until we have \(N_{\rm cf}\) random paths. The Metropolis algorithm applied to \(x_j\) at the \(j^{\rm th}\) site is:
generate a random number \(\zeta \sim U(-\epsilon,\epsilon)\), that is \(\zeta\) is uniformly distributed from \(-\zeta\) to \(+\zeta\), for a constant step size \(\epsilon\) (see later);
replace \(x_j \rightarrow x_j + \zeta\) and compute the change \(\Delta S\) in the action as a result of this replacement (local Lagrangian means this only requires considering a few terms);
if \(\Delta S < 0\) (action reduced) then retain new \(x_j\) and move to the next site;
if \(\Delta S > 0\), generate a random number \(\eta \sim U(0,1)\) (uniform from 0 to 1) and retain the new \(x_j\) if \(e^{-\Delta S} > \eta\), else restore the old \(x_j\); move to the next site.
Comments:
Whether or not many of the \(x_j\)’s do not change in successive paths depends a lot on \(\epsilon\). If \(\epsilon\) is very large, then the changes in \(x_j\) are large and many or most will be rejected; if \(\epsilon\) is very small, then the changes in \(x_j\) are small and most will be accepted, but the path will be close to the same.
Neither situation is good: both slow down the exploration of the space of important paths.
Claim: usually tune \(\epsilon\) so 40% to 60% of the \(x_j\)’s change on each sweep. This implies that \(\epsilon\) is the same order as the typical quantum fluctuations expected.
Because the paths take time to get decorrelated, we should only keep every \(N_{\rm cor}\) path. The optimal value can be determined empirically; here the optimal \(N_{\rm cor}\) depends on \(a\) as \(1/a^2\).
When starting the algorithm, the first configuration is atypical (usually). So we should have a thermalization period where the first paths are discarded. Recommendation: five to ten times \(N_{\rm cor}\) should be discarded.
Higher-order discretization#
Suppose we rewrite the action for one-dimensional quantum mechanics by integrating the kinetic term by parts (assuming \(x(\tau_i)=x(\tau_f)=x\):
The discretization is
where the \(x_j\)’s wrap around at the ends: \(x_0 = x_{N}\), \(x_{-1} = x_{N-1}\), and so on.
Python imports#
First we import standard Python functions.
import numpy as np # use np as shorthand for the numpy package
from numpy.random import uniform, normal # two random number generators, one uniform and one Gaussian
from scipy import integrate # import functions for integration over arrays
import matplotlib.pyplot as plt # basic plotting package
import seaborn as sns; sns.set_style("darkgrid"); sns.set_context("talk") # set up for better looking plots
Classes and functions for path integrals#
These are from Lepage’s lectures. Not yet incorporated here.
1-d potential class#
class Potential:
"""
A general class for nonrelativistic one-dimensional potentials
Parameters
----------
hbar : float
Planck's constant. Equals 1 by default
mass : float
Particle mass. Equals 1 by default
Methods
-------
V(x)
Returns the value of the potential at x.
E_gs
Returns the analytic ground-state energy, if known
wf_gs(x)
Returns the analytic ground-state wave function, if known
plot_V(ax, x_pts)
Plots the potential at x_pts on ax
"""
def __init__(self, hbar=1., mass=1., V_string=''):
self.hbar = hbar
self.mass = mass
self.V_string = V_string
def V(self, x):
"""
Potential at x
"""
print('The potential is not defined.')
def E_gs(self):
"""
analytic ground state energy, if known
"""
print('The ground state energy is not known analytically.')
def wf_gs(self, x):
"""
analytic ground state wave function, if known
"""
print('The ground state wave function is not known analytically.')
def plot_V(self, ax, x_pts, V_label=''):
"""
Plot the potential on the given axis
"""
ax.plot(x_pts, self.V(x_pts), color='blue', alpha=1, label=V_label)
Harmonic Oscillator definitions#
We’ll do the one-dimensional harmonic oscillator (ho), by default in units where the basic quantities are all unity. In these units, the energies should be (n+1/2), where n = 0,1,2,3,…).
class V_HO(Potential):
"""
Harmonic oscillator potential (subclass of Potential)
"""
def __init__(self, k_osc, hbar=1, mass=1, V_string='Harmonic oscillator'):
self.k_osc = k_osc
self.mass = mass
super().__init__(hbar, mass, V_string)
def V(self, x) :
"""Standard harmonic oscillator potential for particle at x"""
return self.k_osc * x**2 /2
def E_gs(self):
"""
1D harmonic oscillator ground-state energy
"""
(1/2) * self.hbar * np.sqrt(self.k_osc / self.mass) # ground state energy
def wf_gs(self, x):
"""
1D harmonic oscillator ground-state wave function
"""
omega = np.sqrt(self.k_osc / self.mass)
const = self.mass * omega / self.hbar # m * omega**2
norm = (self.mass * omega / (np.pi * hbar))**(1/4)
return norm * np.exp(-const * x**2 / 2) # We should put the units back!
class V_aHO(Potential):
"""
Subclass of Potential for anharmonic oscillator.
Parameters
----------
Methods
-------
"""
def __init__(self, k_osc, hbar=1, mass=1, V_string='Anharmonic oscillator'):
self.k_osc = 1
self.mass = mass
super().__init__(hbar, mass, V_string)
def V(self, x) :
"""Anharmonic oscillator potential for particle at x"""
return self.k_osc * x**4 /2
Make some plots#
# Instantiate a harmonic oscillator potential
mass = 1.
k_osc = 1. # oscillator constant
hbar = 1.
test_ho = V_HO(k_osc, hbar, mass)
test_aho = V_aHO(k_osc, hbar, mass)
# Check the SHO wave function and potential
x_pts_all = np.arange(-4., 4., .01)
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel(r'x')
#ax.set_ylabel(r'g(x)')
ax.set_xlim(-4., 4.)
ax.set_ylim(-0.1, 1.)
ax.axhline(0., color='black', alpha=0.5, linestyle='dotted')
test_ho.plot_V(ax, x_pts_all, V_label='HO potential')
ax.plot(x_pts_all, test_ho.wf_gs(x_pts_all), color='red', alpha=1, label='gs wf')
ax.set_title(f'{test_ho.V_string} with k_osc = {k_osc:.1f}, mass = {mass:.1f}')
ax.legend()
fig.tight_layout()
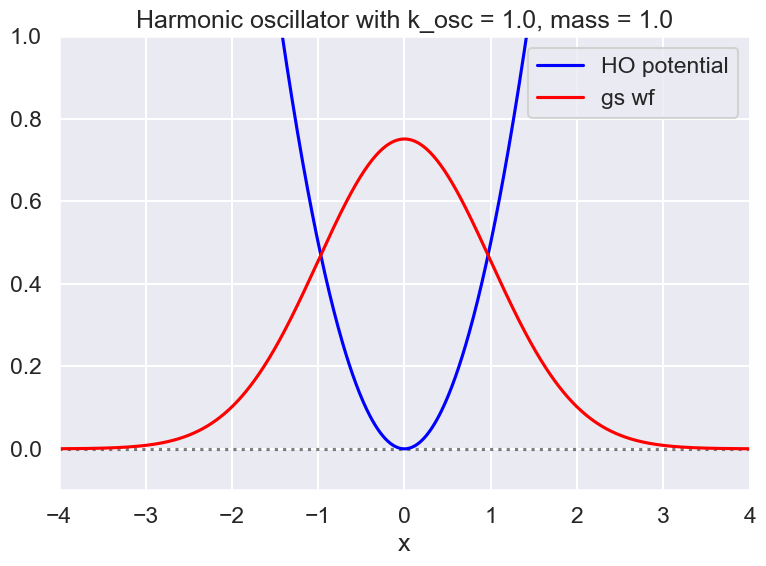
# Normalization check of wave function squared
integrate.simps(test_ho.wf_gs(x_pts_all)**2, x_pts_all)
0.9999999839221155
Metropolis calculation (section 2.2 of Lepage lectures)#
We include these notes for references, although they are not implemented in this notebook.
Now instead of an integration over all paths, we want to select a representative sampling of the “paths” that are distributed according to \(e^{-S[x]}\). If we succeed, we can take an unweighted average over these paths to approximate the weighted average over uniformly distributed paths.
We will use the Metropolis algorithm to generate a sequence of paths.
Define a function to initialize the first path, which is set to zero at each of the Npts times:
We update the path following the Metropolis algorithm:
Step through each time point from j = 0 to Npts-1
Save the value of the path at current time point j
Calculate the current value of the action (only considering contributions that depend on j with speed)
Generate a random number xi from -epsilon to epsilon and consider x_j –> x_j + xi
Find Delta S (change in the action) for this change:
a. If Delta S < 0 (action reduced), keep new x_j and go to next value of j.
b. If Delta S > 0 (action increased), generate eta between 0 and 1. Keep new x_j if exp(-Delta S) > eta, otherwise keep old value and move on to the next j.In general we keep track of the “success” rate and adjust epsilon so that it is about 50% successes.
Class for path integral#
# Modules needed for example: emcee is for MCMCsampling, corner for plotting
from scipy import stats
import emcee
import corner
class PathIntegral:
"""
A class for a path integral for 1D quantum mechanics. Associated with an
instance of the class is:
* a potential with the Potential superclass but a particular subclass
* a lattice definition
* settings for correlation and thermalization "times" (Monte Carlo steps)
* method for updating
* method for averaging
* list of configurations (paths)
* choice of by-hand Metropolis updating or using emcee, zeus, or pyMC3
"""
def __init__(self, Delta_T=0.25, N_pts=20, N_config=100, N_corr=20, eps=1.4,
V_pot=None):
self.Delta_T = Delta_T # DeltaT --> "a" in Lepage
self.N_pts = N_pts # N_pts --> "N" in Lepage
self.T_max = Delta_T * N_pts # Tmax --> "T" in Lepage
self.N_config = N_config
self.N_corr = N_corr
self.eps = eps
self.V_pot = V_pot # member of Potential class
#self.x_path = np.zeros(self.N_pts)
#self.list_of_paths =
def S_lattice(self, x_path):
"""
Contribution to the action from path x_path
"""
action = 0
for j in range(0, self.N_pts):
j_plus = (j + 1) % self.N_pts
x_j = x_path[j]
x_j_plus = x_path[j_plus]
action = action + self.Delta_T * self.V_pot.V(x_j) \
+ (self.V_pot.mass/(2*self.Delta_T)) * (x_j_plus - x_j)**2
return action
def H_lattice_j(self, x_path, j):
"""
Contribution to the energy from time point j
"""
j_plus = (j + 1) % self.N_pts
x_j = x_path[j]
x_j_plus = x_path[j_plus]
return self.Delta_T * self.V_pot.V(x_j) \
+ (self.V_pot.mass/(2*self.Delta_T)) * (x_j_plus - x_j)**2
def E_avg_over_paths(self, list_of_paths):
"""
Average the lattice Hamiltonian over a set of configurations in
list_of_paths.
"""
N_paths = len(list_of_paths)
#print('Npaths = ', N_paths)
E_avg = 0.
for x_path in list_of_paths:
for j in range(N_pts):
E_avg = E_avg + self.H_lattice_j(x_path, j)
return E_avg / (N_paths * self.N_pts)
Discretize time#
Delta_T = 0.25 # DeltaT --> "a" in Lepage
N_pts = 20 # N_pts --> "N" in Lepage
Tmax = Delta_T * N_pts # Tmax --> "T" in Lepage
# Do we need the following with emcee?
# Probably not, but available for the future.
N_config = 100
N_corr = 20 # Lepage recommends 20 or so
eps = 1.4 # suggested epsilon
Test of emcee#
We’ll take \(\theta\) to be the values of \(x\) at each of the N_pts time points. We’ll choose the prior to be uniform in a reasonable range of \(x\). Lepage suggests \(-5 \leq x \leq +5\) is large enough to have negligible effect. Here X will be data.
# Instantiate a new path integral object
new_PI = PathIntegral(Delta_T=Delta_T, N_pts=N_pts, N_config=N_config,
N_corr=N_corr, eps=eps, V_pot=test_ho)
# Set up the probability distributions for emcee and zeus
# range of x values
x_min = -5.
x_max = +5.
# theta is a vector of parameters that we use to represent a path
# There are N_pts x values in the path; theta is a vector for a
# particular path.
min_theta = x_min * np.ones(N_pts)
max_theta = x_max * np.ones(N_pts)
volume_theta=np.prod(max_theta-min_theta) # For normalization
def log_prior(theta):
'''
In the general application, the log prior for parameter array theta.
For path integrals, it is a uniform distribution in [x_min, x_max]
'''
assert len(theta)==N_pts, "Parameter vector must have length N_pts."
# flat prior ("flat" means uniform probability)
if np.logical_and(min_theta<=theta, theta<=max_theta).all():
return np.log(1/volume_theta)
else:
return -np.inf
def log_likelihood(theta, path_integral):
'''
Log likelihood for path integral given parameter array theta
is minus the action for that path. The action is specificed
in the passed PathIntegral object.
'''
try:
return -path_integral.S_lattice(theta)
except ValueError:
return -np.inf
def log_posterior(theta, path_integral):
'''
Log posterior for path integral given parameter array theta.
Just the log of the product of prior and likelihood.
'''
return log_prior(theta) + log_likelihood(theta, path_integral)
path_integral = new_PI # just a synonym for new_PI
N_corr = 20 # Lepage recommends 20 or so
ndim = N_pts # number of parameters in the model
nwalkers = 50 # number of MCMC walkers
nburn = 50 * N_corr # "burn-in" period to let chains stabilize
nsteps = 10000 # number of MCMC steps to take
# Uncomment to start at random locations within the prior volume
# starting_guesses = min_theta + \
# (max_theta - min_theta) * np.random.rand(nwalkers,ndim)
# Uncomment to start with a normal distribution with mean zero and width x_max/10.
starting_guesses = (x_max/10) * np.random.randn(nwalkers,ndim)
print(f"MCMC sampling using emcee (affine-invariant ensamble sampler) with {nwalkers} walkers")
sampler = emcee.EnsembleSampler(nwalkers, ndim, log_posterior, args=[path_integral])
# "burn-in" period; save final positions and then reset
pos, prob, state = sampler.run_mcmc(starting_guesses, nburn)
sampler.reset()
# sampling period. nsteps * nwalkers is the number of configutions.
sampler.run_mcmc(pos, nsteps)
print("Mean acceptance fraction: {0:.3f} (in total {1} steps)"
.format(np.mean(sampler.acceptance_fraction),nwalkers*nsteps))
# discard burn-in points and flatten the walkers; the shape of samples is (nwalkers*nsteps, ndim)
samples = sampler.chain.reshape((-1, ndim))
MCMC sampling using emcee (affine-invariant ensamble sampler) with 50 walkers
Mean acceptance fraction: 0.299 (in total 500000 steps)
# tau = sampler.get_autocorr_time()
# print(tau)
# Calculate the energy averaged over all the configurations (no thinning)
print(samples.shape)
E_avg = new_PI.E_avg_over_paths(samples)
print(f'Average over {int(nwalkers*nsteps)} configurations is {E_avg:.5f}')
(500000, 20)
Average over 500000 configurations is 0.49807
# Calculate the energy averaged over thinned configurations (every N_corr)
samples_thinned = sampler.get_chain(discard=0, flat=True, thin=N_corr)
print(samples_thinned.shape)
E_avg = new_PI.E_avg_over_paths(samples_thinned)
print(f'Average over {int(nwalkers*nsteps/N_corr)} configurations is {E_avg:.5f}')
(25000, 20)
Average over 25000 configurations is 0.49849
# Make a corner plot with the posterior distribution
labels = [f"{str:.0f}" for str in range(N_pts)]
fig = corner.corner(samples_thinned, labels=labels,
quantiles=[0.16, 0.5, 0.84],
show_titles=True, title_kwargs={"fontsize": 12})

# Check the wave function for the harmonic oscillator
# Compare analytic wf to the histogrammed version.
x_pts_all = np.arange(-4., 4., .01)
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel(r'x')
#ax.set_ylabel(r'g(x)')
ax.set_xlim(-4., 4.)
#ax.set_ylim(-0.1, 1.)
ax.axhline(0., color='black', alpha=0.5, linestyle='dotted')
#test_ho.plot_V(ax, x_pts_all, V_label='HO potential')
ax.plot(x_pts_all, test_ho.wf_gs(x_pts_all)**2, color='red', alpha=1, label=fr'(gs wf)${{}}^2$')
ax.hist(samples.flatten(), bins=np.arange(x_min, x_max, .1), density=True)
ax.set_title(f'{test_ho.V_string} with k_osc = {k_osc:.1f}, mass = {mass:.1f}')
ax.legend()
fig.tight_layout()
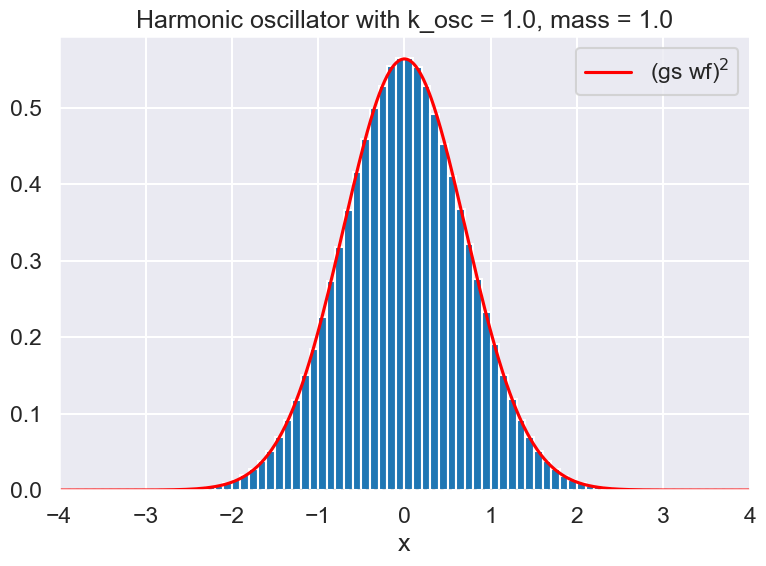
Try with zeus#
Same calculation but with a different MCMC package, called Zeus. It is an ensemble slice sampler.
The setup is very similar to emsee, with some differences in commands for carrying out the sampling.
import zeus
path_integral = new_PI # just a synonym for new_PI
N_corr = 20 # Lepage recommends 20 or so
ndim = N_pts # number of parameters in the model
nwalkers = 50 # number of MCMC walkers
nburn = 10 * N_corr # "burn-in" period to let chains stabilize
nsteps = 10000 # number of MCMC steps to take
# Uncomment to start at random locations within the prior volume
# starting_guesses = min_theta + \
# (max_theta - min_theta) * np.random.rand(nwalkers,ndim)
# Uncomment to start with a normal distribution with mean zero and width x_max/10.
starting_guesses = (x_max/10) * np.random.randn(nwalkers,ndim)
# Do the burn-in with nburn steps
print(f"MCMC sampling using zeus (ensamble slice sampler) with {nwalkers} walkers")
sampler = zeus.EnsembleSampler(nwalkers, ndim, log_posterior, args=[path_integral])
sampler.run_mcmc(starting_guesses, nburn)
# Get the burn-in samples
burnin = sampler.get_chain()
# reset the start
starting_guesses = burnin[-1]
# now do the post-burn-in sampling with nsteps steps
sampler = zeus.EnsembleSampler(nwalkers, ndim, log_posterior, args=[path_integral])
sampler.run_mcmc(starting_guesses, nsteps)
Initialising ensemble of 50 walkers...
MCMC sampling using zeus (ensamble slice sampler) with 50 walkers
Sampling progress : 100%|████████████████████| 200/200 [00:01<00:00, 134.78it/s]
Initialising ensemble of 50 walkers...
Sampling progress : 100%|█████████████████| 10000/10000 [02:42<00:00, 61.56it/s]
# Average the energy over thinned samples
chain_thinned = sampler.get_chain(discard=0, flat=True, thin=N_corr)
print(chain_thinned.shape)
E_avg = new_PI.E_avg_over_paths(chain_thinned)
print(f'Average over {int(nwalkers*nsteps/N_corr)} thinned configurations is {E_avg:.5f}')
(25000, 20)
Average over 25000 thinned configurations is 0.49964
# Average the energy over unthinned samples
chain = sampler.get_chain(flat=True, discard=0, thin=1)
chain.shape
E_avg = new_PI.E_avg_over_paths(chain)
print(f'Average over {int(nwalkers*nsteps)} configurations is {E_avg:.5f}')
Average over 500000 configurations is 0.49939
Let’s look at some paths#
That is, if we look at a particular index and all the second indices for a chain, e.g., chain_thinned(1000, :), this is the series of \(x\) values at the N_pts values of \(\tau\). That is, it is one of the sampled paths. Here we look at num_plots paths. Try changing this number (e.g., to 20 or 200). The parameter skip_points determines where to start looking at paths.
What happens if you use chain instead of chain_thinned?
# Delta_T = 0.25 # DeltaT --> "a" in Lepage
# N_pts = 20 # N_pts --> "N" in Lepage
# Tmax = Delta_T * N_pts # Tmax --> "T" in Lepage
# Make an array
T_pts = np.arange(0,Tmax+Delta_T,Delta_T)
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel(r'$\tau$')
ax.set_ylabel(r'$x$')
ax.set_ylim(-2.5, 2.5)
num_plots = 20
colors = plt.cm.jet(np.linspace(0,1,num_plots))# Initialize holder for trajectories
for plot_num in range(num_plots):
skip_points = 1500
chain_plot = np.append(chain_thinned[plot_num + skip_points,:], chain_thinned[plot_num + skip_points,0])
# chain_plot = np.append(chain[plot_num + skip_points,:], chain[plot_num + skip_points,0])
ax.scatter(T_pts, chain_plot, color=colors[plot_num], marker='.', linewidth=3, alpha=1)
ax.plot(T_pts, chain_plot, color=colors[plot_num], alpha=0.3)
ax.set_title(f'{test_ho.V_string} with k_osc = {k_osc:.1f}, mass = {mass:.1f}')
fig.tight_layout()
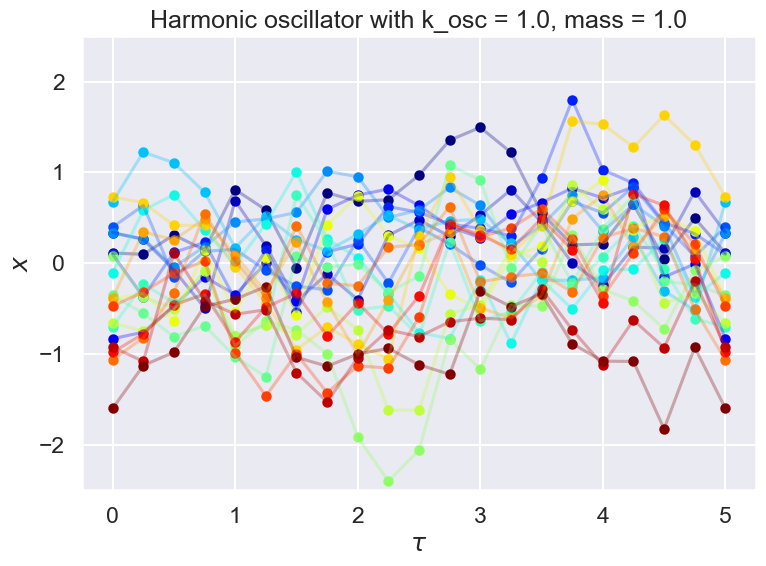
Let’s go ahead with the unthinned chain. Highly correlated!#
# Delta_T = 0.25 # DeltaT --> "a" in Lepage
# N_pts = 20 # N_pts --> "N" in Lepage
# Tmax = Delta_T * N_pts # Tmax --> "T" in Lepage
# Make an array
T_pts = np.arange(0,Tmax+Delta_T,Delta_T)
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel(r'$\tau$')
ax.set_ylabel(r'$x$')
ax.set_ylim(-2.5, 2.5)
num_plots = 20
colors = plt.cm.jet(np.linspace(0,1,num_plots))# Initialize holder for trajectories
for plot_num in range(num_plots):
skip_points = 1500
# chain_plot = np.append(chain_thinned[plot_num + skip_points,:], chain_thinned[plot_num + skip_points,0])
chain_plot = np.append(chain[plot_num + skip_points,:], chain[plot_num + skip_points,0])
ax.scatter(T_pts, chain_plot, color=colors[plot_num], marker='.', linewidth=3, alpha=1)
ax.plot(T_pts, chain_plot, color=colors[plot_num], alpha=0.3)
ax.set_title(f'{test_ho.V_string} with k_osc = {k_osc:.1f}, mass = {mass:.1f}')
fig.tight_layout()
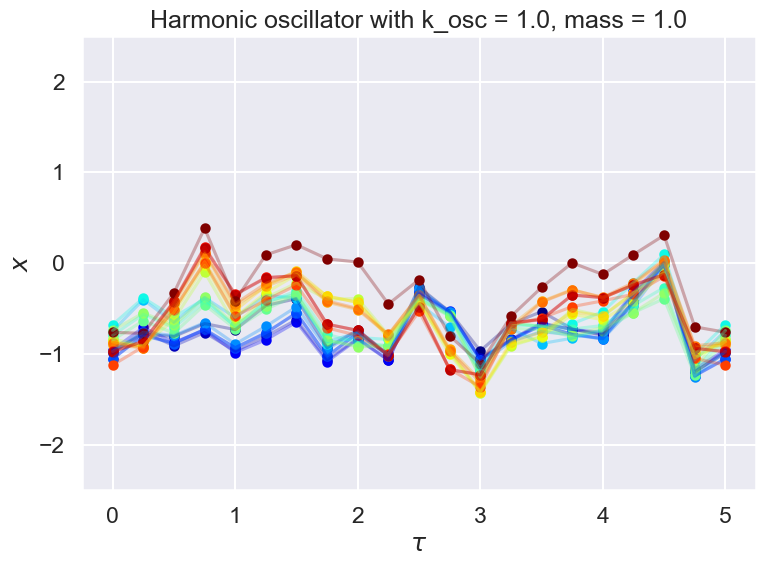
# Plot sequences of x values for each time point
plt.figure(figsize=(16,1.5*ndim))
for n in range(ndim):
plt.subplot2grid((ndim, 1), (n, 0))
plt.plot(sampler.get_chain()[:,:,n],alpha=0.5)
#plt.plot(chain[:,n],alpha=0.5)
#plt.axhline(y=mu[n])
plt.tight_layout()
plt.show()
T_pts = np.arange(0,Tmax+Delta_T,Delta_T)
print(Delta_T)
print(T_pts.shape)
print(T_pts)
0.25
(21,)
[0. 0.25 0.5 0.75 1. 1.25 1.5 1.75 2. 2.25 2.5 2.75 3. 3.25
3.5 3.75 4. 4.25 4.5 4.75 5. ]
plt.figure(figsize=(16,1.5*ndim))
for n in range(ndim):
plt.subplot2grid((ndim, 1), (n, 0))
#plt.plot(sampler.get_chain()[:,:,n],alpha=0.5)
plt.plot(chain[:,n],alpha=0.5)
#plt.axhline(y=mu[n])
plt.tight_layout()
plt.show()

# make a corner plot with the posterior distribution
fig = corner.corner(chain, labels=labels,
quantiles=[0.16, 0.5, 0.84],
show_titles=True, title_kwargs={"fontsize": 12})

# # Try the zeus corner plot routine, using every 10
# fig, axes = zeus.cornerplot(chain[::10], size=(8,8))
Trying a larger lattice spacing a#
# Delta_T = 0.50 # Delta_T --> "a" in Lepage
# N_pts = 20 # N_pts --> "N" in Lepage
# Tmax = Delta_T * N_pts # Tmax --> "T" in Lepage
# N_config = 4000 # We'll want to try 25, 100, 1000, 10000
# N_corr = 20 # Lepage recommends 20 or so
# eps = 1.4 # suggested epsilon
# new_PI = PathIntegral(Delta_T=Delta_T, N_pts=N_pts, N_config=N_config,
# N_corr=N_corr, eps=eps, V_pot=test_ho)